Blogs
The latest cybersecurity trends, best practices, security vulnerabilities, and more

No symbols? No problem!
By Trellix · August 9, 2024
This blog was written by Max Kersten
Malware analysts know it all too well: the ominous feeling that washes over you when opening an unknown file in your favorite analysis tool and being greeted with hundreds or thousands of unknown functions, none of which are matched by your existing function signatures nor any of your helper scripts. This makes analysis a painfully slow and tedious process. It also often means the required analysis time exceeds the available time, and another file is chosen to be reversed instead. This undesired scenario creates a blind spot from a blue team’s perspective and rings especially true when dealing with malware.
This blog will share a tried and tested method for dealing with thousands of unknown functions in a given file to significantly decrease the time spent on analysis while improving accuracy. Once all theory is covered, an instance of the Golang based qBit stealer is analyzed with the demonstrated techniques to show what happens when the theory is put into practice. This approach is not restricted to Golang based binaries, as any type of binary falls within the scope of this research. Last, the methodology, based on the shared theory and scripts, is outlined in a flowchart to allow others to reuse and improve upon.
While generated function symbols are portable, an aggregation scales very well over any number of analysts. As such, this methodology works well for individual researchers, but when scaling it for a team of researchers, the outcome will be greater than the sum of its parts.
The content in this blog focuses on Ghidra, given its free and open-source nature, as well as some of the features it inherently has, such as BSim. The Ghidra scripts mentioned in this blog can be found on our GitHub, as can the open-sourced FunctionID and BSim databases and signatures. Additionally, the referenced Golang binaries with the complete runtime per Golang version and architecture can be found there.
Summary
This blog dives into background information of function symbols and Ghidra’s internals. To allow people with a variety of technical backgrounds to understand, the first few sections will cover said background information. From the “Symbol recovery” section onwards, Ghidra’s internals will be included. The rest of the summary is intended for those who are familiar with Ghidra’s terminology, such as FunctionID and BSim. For those who aren’t, feel free to skip this section and continue as you were.
Ghidra’s FunctionID feature is designed especially to detect and automatically rename unnamed functions. BSim, short for Behavioral Similarity, is another Ghidra feature, intended for analysts to check the decompiled code of a similar function. Both features rely on signatures which are made from known binaries. The more signatures, the more functions Ghidra can rename and compare. Below we’ve included information on the number of FunctionID and BSim signatures along with additional context.
The generated FunctionID signatures are listed below in descending order. Hyperlinked projects link to the original binaries which one can download to replicate these figures.
| Project name | FunctionID signature count |
| Golang (first available version through 1.21) | 48,472,262 |
| Boost (1.65.0 through 1.84.0) | 28,191,439 |
| libxml2 | 1,608,164 |
| openssl | 818,210 |
| libgcrypt | 673,280 |
| libnettle | 447,443 |
| liblzma | 108,279 |
| msvc-empty | 86,479 |
| uclibc (from Enterprise Linux 7 and 8, and Ubuntu) | 47,394 |
| libzlib | 16,292 |
| libsodium (from Enterprise Linux 7 and 8m and Ubuntu) | 16,093 |
| avr-libc (from Enterprise Linux 7 and 8, and Ubuntu) | 15,616 |
| libbzip2 | 7,433 |
| Total | 80,508,384 |
When creating BSim signatures, the total number of signatures is not returned. As such, no specific signature count can be given. Given how the number of original files and their size correlate somewhat to the BSim function signature count, the descending order in the table above likely matches the number of BSim function signatures for each project. In total, nearly 118 gibibytes of signatures have been created.
Symbols 101
When writing code, namespaces, classes, functions, and variables are given recognizable, self-explanatory, unambiguous names. As such, one can easily understand, interpret, and work with someone else’s code. Additionally, coding standards and linters can be used to ensure and enforce agreements which have been made.
In reality, the compiler does not require symbols at all. The compiled code depends on (relative) addresses, all of which are handled in a lossy process. The compiled binary, also known as a build, can contain the original symbols. Such a build is often referred to as a debug build. The symbols can be omitted from the build during compile time which can be referred to as a stripped or release build. For more in-depth information on the inner workings of compilers and the usage of symbols, please refer to the talks from Anders Schau Knatten at NDC TechTown in 2021 and 2023.
When compiling a stripped build, a file which maps the symbols from the source to the addresses within the binary is created. There are several formats for such files, such as the Program DataBase (PDB) and DWARF. These files can be loaded by debuggers and other analysis frameworks which support them and show the symbols during debugging to find and/or resolve errors.
Malware is usually spread in the form of stripped builds. The additional debug symbol file is not spread along with said malware as it serves no benefit for the malicious actor. It is even possible the debug symbol file can help with the attribution of the malware, as it contains specific and additional metadata.
To illustrate, the operational security of the threat actor named Rubella (who was responsible for the creation and maintenance of the Dryad Macro Builder) was suboptimal as the PDB file was found and used to obtain a copy of the builder. Uncovering a PDB file does not always lead to such a finding, which is demonstrated in our past research.
Types of code
From a reversing perspective, there are three different types of code within each binary although not all of them are present in every binary. The three types of code are runtime, library, and user. For each of these, having symbols would be beneficial during the analysis of a sample. Alas, symbols are often missing, regardless of the type of code.
Runtime code relates to the runtime of the programming language, such as C++ or Golang. This code is partially executed during startup of the binary, and used during the execution. Reversing this code can be required to understand another function, but it is easy (and common) to not see the forest for the trees. As such, valuable time is lost while reversing benign code without proper symbols.
Library code is found within binaries which use libraries to perform certain tasks. In this case, the library code would have to be statically linked, meaning the library’s code is included within the binary, and not present in a separate library file such as a Dynamic Link Library (DLL) or a Shared Object (SO) file. Much like the runtime code, understanding the used libraries during the analysis of a sample is helpful, while reversing the same code without symbols is a tedious and time consuming process.
User code is the core of the program at hand. It uses the runtime and library code, along with additional arbitrary code, to perform actions the author wants it to. This is the code on which the analyst will focus most. Having the symbols for the runtime and library code will make this process more efficient, where not having such symbols will make this process tedious and slow. Needless to say, having symbols for the user code is the most valuable, but also a rare occurrence.
When reverse engineering a program, one should keep the development process in mind. Doing so will create a clearer mental image of the program and allow one to structure the program’s functions into any of the three above-mentioned types. To effectively and efficiently analyze code, it helps to recognize reused code as it will put the code into perspective and can save time during the analysis. Speeding up the analysis will happen more easily if the code reuse is detected automatically.
Recognizing code reuse
Recognizing reused code is, in and of itself, not necessarily a finding, as it depends on the type of reused code as well as the goal of the research. A few examples are listed below.
- A binary without an embedded runtime nor any included libraries which overlap with a similar binary is likely worthwhile to look into, as the overlap likely occurs in the user code
- The usage of a specific runtime (version) or the usage of a specific library might be a goal on its own, i.e. when looking for a specific vulnerable version
- Finding the difference between two versions of the same file, also known as patch diffing, makes any type of code overlap (or lack thereof) between the files potentially interesting
The specific reason to look for code reuse differs on a case-by-case basis. Aside from the examples above, Acid wipers and the evolution of Kuiper ransomware are discussed respectively to further illustrate the importance of recognising code reuse. Each of the links refers to previous Trellix blogs, for those interested in more background information.
Acid wiper code overlap
The overlap found between AcidRain and AcidPour, as highlighted in the image below, is mostly based on the usage of the uClibc (or uClibc-ng) library. The reuse of the uClibc(-ng) related code does not indicate that AcidRain and AcidPour are created by the same actor per se, but it is an interesting finding nevertheless.
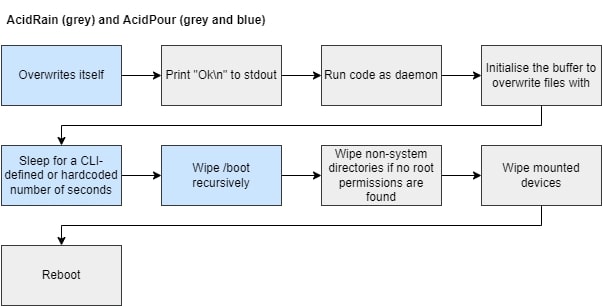
The newly added user based code and the recursive wiping of the boot folder are new in AcidPour compared to AcidRain. Having the symbols for the runtime made the analysis easier since user code is easy to distinguish from included the runtime and library code, and the user code is not labeled, whereas other functions are. Additionally, the new functions were easier to understand as most of the called library functions had been renamed already.
Transferring symbols from one program to another is possible, but the difference in architecture makes it difficult to do so while maintaining accurate results. The runtime and library symbols have been obtained by getting the symbols from binaries that were compiled for a matching version, architecture, and operating system.
While the majority of the code overlap within AcidPour comes from the used library, the wiping of non-system directories does overlap. Recognizing the overlap between the code is not as easy as expected for two ELF files since the architectures of both binaries are different. Where AcidRain is targeted for 32-bit MIPS, AcidPour is targeted for x86. As such, the code overlap is more easily spotted manually, or if symbols for the used libraries are present for both architectures when analyzing the files.
Kuiper ransomware’s evolution
This ransomware family is Golang based, meaning the runtime is included within the compiled binary. As such, looking for code overlap between a Kuiper sample and other files is likely to lead to false positives, as the Golang 1.18 runtime got released in March 2022 and is still actively used. Additionally, (first few) versions thereafter have changed, but the majority of the runtime is still similar, if not identical, to the 1.18 runtime.
The Kuiper versions A, B, and C, incremented slightly over time. Comparing the code manually is possible due to the low number of samples, and allows for an easy comparison between Windows, Linux, and MacOS targeting binaries, as is explained in great detail in the original blog.
When relying on automated processes, the identification of the Golang runtime and/or used libraries can be done based on publicly available data for which function signatures are then created. The analyzed user code can be used to generate signatures from, assuming meaningful names have been assigned to relevant functions.
Some functions are split into multiple different smaller functions by the Golang compiler. This is done for multiple reasons though out of scope for this blog. A large function might change when a binary is updated especially if said function is user code. When split into parts, the likelihood of each smaller function changing is low, meaning that some functions might still match. This can give the analyst a hint as to what is happening.
The downside here is the failure to create signatures for functions which are too small, as such a signature would become too generic. Golang’s stack check in the beginning of each function makes it unlikely that a function is too small to create a signature for. This can lead to conflicts with regards to function signatures, since this could lead to multiple names for the same signature.
Symbol recovery
Recovering function symbols can be done in a variety of ways. Usually, these symbols are recovered via function signatures, but sometimes stripped binaries themselves contain information to restore function names. Function signatures and/or the usage of information within a given binary can be used separately or complimentary. The combination generally yields the most complete results whenever possible, but this is not to say all symbols can be recovered. The number of symbols that can be recovered depends on the used signature database(s), along with the way the binary has been constructed.
Compiling source code is an inherently lossy process. This is especially true for stripped binaries, as the original symbols are lost completely without the aforementioned symbol data. As such, reverse engineering is not always 100% accurate when comparing it to the source code, especially when taking compiler optimization into account.
The features discussed in this blog, FunctionID and BSim, are of great help when recovering symbols, they are not always correct nor complete. Misidentified or missing symbols can (and likely will) still occur over time. These techniques have, however, proven themselves to be trustworthy and greatly decrease the amount of time required to analyze files.
Metadata
Even stripped binaries contain metadata, often to provide help with crash reports and/or because the runtime requires the metadata to function properly. To illustrate, Golang files contain symbol related information within the program-counter line-number table (pclntab), which can be used to recover symbols for functions and types. A previous blog and talk explain the how and why in detail. In short, this information was previously used to link source code line numbers to crashes. While this has since changed over time, the metadata is still present.
Function signatures are derived by mapping a function and its name. Simply put: the hash of each function is mapped with its name. This can cause false positives, for example in functions which aren’t large enough. Ghidra adheres to a four CodeUnit lower limit for a function to be taken into account to avoid false positives for functions which are too small.
Within Ghidra, function signatures are handled using FunctionID databases (FIDBs), in which information of matches is stored.
FunctionID databases
When files with symbols have been collected, imported into a Ghidra project, and analysed, one can populate a new FunctionID database to create and store the names and respective hashes of all eligible functions. Each program within a Ghidra project is of a specific ‘type’ and architecture. Within Ghidra, this information is stored within a program’s LanguageID. Compiler related information is stored in the compiler specification.
LanguageIDs and CompilerSpecs
Each entry within a FunctionID database is tied to a specific architecture, binary type, and compiler. This way, a match from a function in one binary (say, 64-bit PowerPC architecture based) which coincidentally is also the result of a different function in another binary (say, 32-bit MIPS architecture based) is not considered as a possibility, thus avoiding a false positive match. Additionally, this ensures Ghidra skips function signature databases for a different LanguageID.
This does, however, mean that it is vital that binaries are loaded correctly by the analyst and/or the auto-detection within Ghidra. The format of the architecture, binary type, and compiler are stored as “processor:variant:size:endianness:compiler” as shown in the excerpt from Ghidra’s overview below.
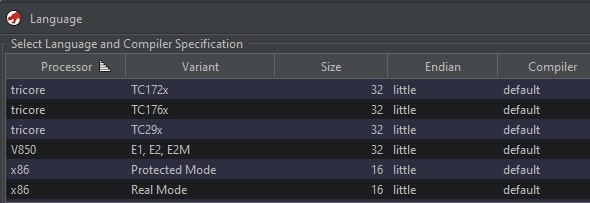
The LanguageID is a case sensitive string which contains all aforementioned fields, such as: “x86:LE:32:default”. The compiler specification (often shortened to “cspec”) is also a case sensitive string when used on its own.
Creating a FunctionID database
As of July 2024, the generation of a FunctionID database is restricted to a single compiler specification for all binaries to be made function signatures in a single go. The check for this resides within FidServiceLibraryIngest’s create function, more details about which can be found in a relevant GitHub issue. A custom Ghidra build without this check can resolve this issue, or one has to ensure all imported programs are of the same specification within the same project.
The custom build might cause slightly decreased accuracy for the generated results. Based on using the generated databases, no significant decrease has been observed, although this is circumstantial evidence. Keep the status of the issue and/or the need to either align all compiler specifications in mind when generating function signatures.
To create a FunctionID database with the script, one needs to run Ghidra and provide several function parameters. When running Ghidra headless, the script relies on command-line arguments, rather than the graphical user interface prompts. Ghidra’s headless execution scripts can be found in the “support” folder in the root of Ghidra’s installation folder and is named “analyzeHeadless”. The file extension differs based on the used operating system, i.e. “analyzeHeadless.bat” on Windows. More information about Ghidra’s headless execution can be found here.
The required arguments are listed in the table below, in the required order. Note that no flags are used, merely the argument values.
| Argument | Details |
| Project name | A string with the project name to be included within the FIDB |
| Project version | A string with the project version to be included within the FIDB |
| Output folder | The folder to output the FIDB file(s) and log to |
| Common symbols | A boolean (either “true” or “false”) to indicate if common symbols are to be excluded |
| Common symbols file | Only used if the common symbols boolean is true! A path to a file which contains function names to be excluded from the FIDB, one function name per line within the file |
An example command-line interface command is: “.\analyzeHeadless.bat C:\Users\user fidb-test -postScript AutomaticallyCreateFunctionIdDatabases projectName projectVersion C:\Users\user\Desktop\fidb false”.
In the command above, the first argument is the path to the folder where the Ghidra project resides, and the second argument is the Ghidra project name. No other actions are desired by Ghidra, so only the postscript flag is used to indicate that once everything is done, a given script is to be executed, which is then specified. Once the script name has been provided, it is assumed Ghidra knows the location of the script, otherwise one has to specify the “-scriptPath” flag with a path to the folder where the script is located. Command-line arguments following the script are used by the script.
The output of the script is displayed in the terminal, although this is usually not the best option to review the results. The “log.txt” file in the output folder also contains the script’s output. The reason to prefer the file over the terminal once the execution has finished, is the printing of missing symbols, where each missing symbol is printed on a new line. This will quickly exhaust the terminal’s buffer, making it impossible to scroll back up. The screenshot below shows the output, without the missing symbols, of a demo run.

In the top half of the image, the provided project name, project version, and output folder are printed, providing feedback to the analyst. It then states all discovered LanguageIDs and their versions, after which it will create a FIDB for the files of each LanguageID. The bottom half displays the total number of visited, added, and excluded functions.
For all excluded functions, a distinction is made based on the exclusion reason. The reasons are listed below.
- A failed function for any reason results in the FAILED_FUNCTION_FILTER exclusion
- If the memory within the program cannot be accessed, a memory access exception is thrown, resulting in the MEMORY_ACCESS_EXCEPTION exclusion
- If a function is a thunk function within the program, it is excluded as IS_THUNK
- If the function’s length does not exceed the aforementioned four CodeUnit length, its length is too short, and it is excluded as FAILS_MINIMUM_SHORTHASH_LENGTH
- A duplicate hash will result in an exclusion as only one name can be mapped to a hash within a single generation run. These exclusions are marked as DUPLICATE_INFO
The resulting FIDB file can be attached to Ghidra and is ready to be used. Note that the naming scheme of the FIDB file is based on the given project name, project version, and LanguageID, for each LanguageID within the project. If different compiler specifications are present and the aforementioned compiler specification check is present, an error will be thrown and no FIDB file will be created.
Ready-to-use FunctionID databases are generally limited in size, usually less than 10 megabytes, or a few hundred megabytes if a large number binaries with a lot of symbols per binary are stored within a single database. Regardless of the specifics, the databases are easy to share among researchers, be it within the same organization and/or publicly. The latter has been done by Threatrack on GitHub. Their work on FunctionID database generation has inspired the FunctionID generation script that is released in tandem with this blog.
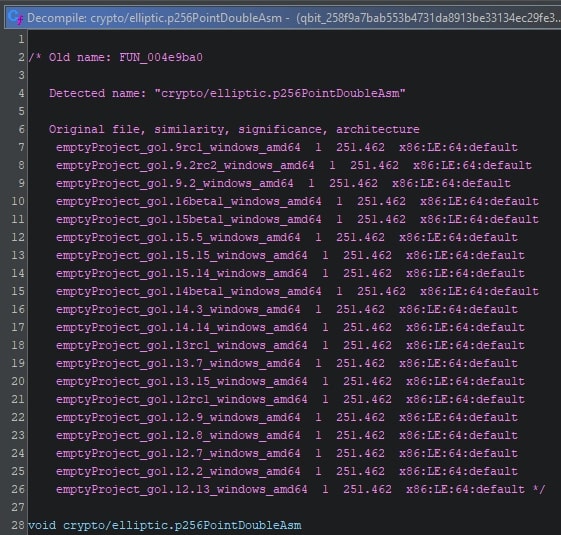
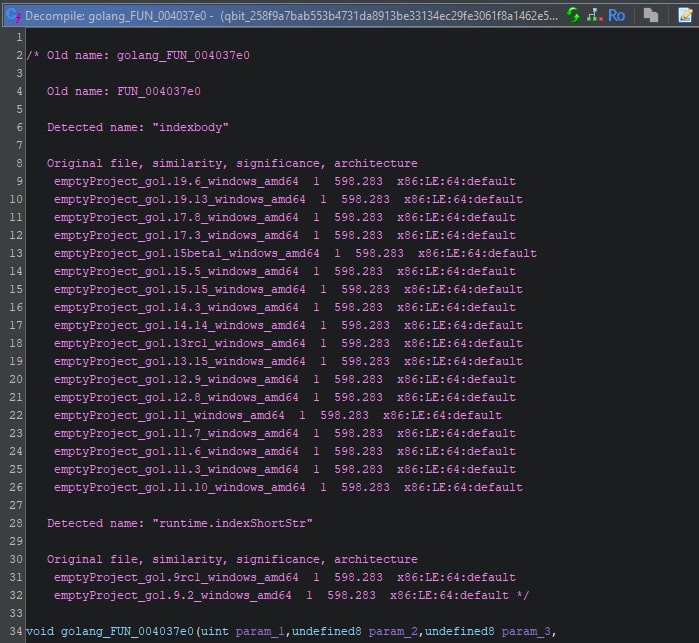
To illustrate the difference a FunctionID can make, one can look at a function before and after applying the FunctionID signatures. The image given below is a Golang runtime function.
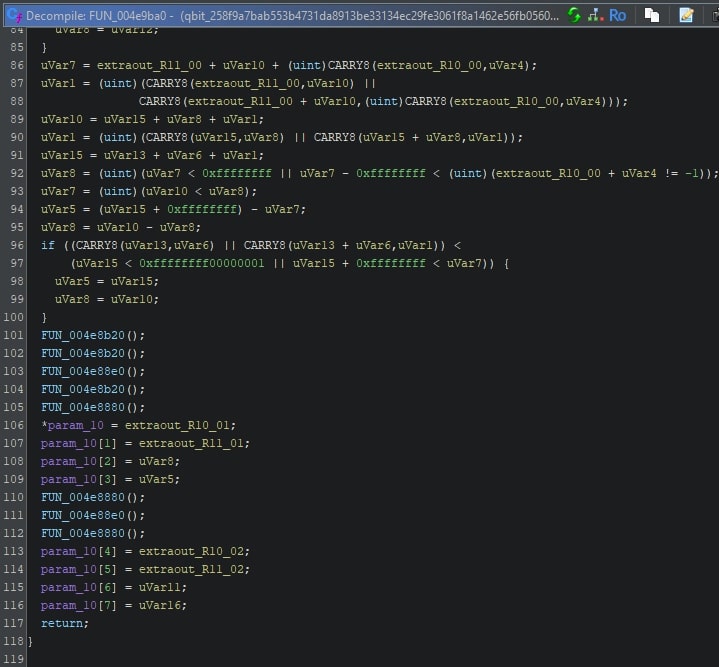
This function calls three different functions: FUN_004e8b20, FUN_004e8b20, and FUN_004e8880. Once the FunctionID signatures are applied, the function named FUN_04e8880 is renamed to p256SubInternal, as can be seen below.
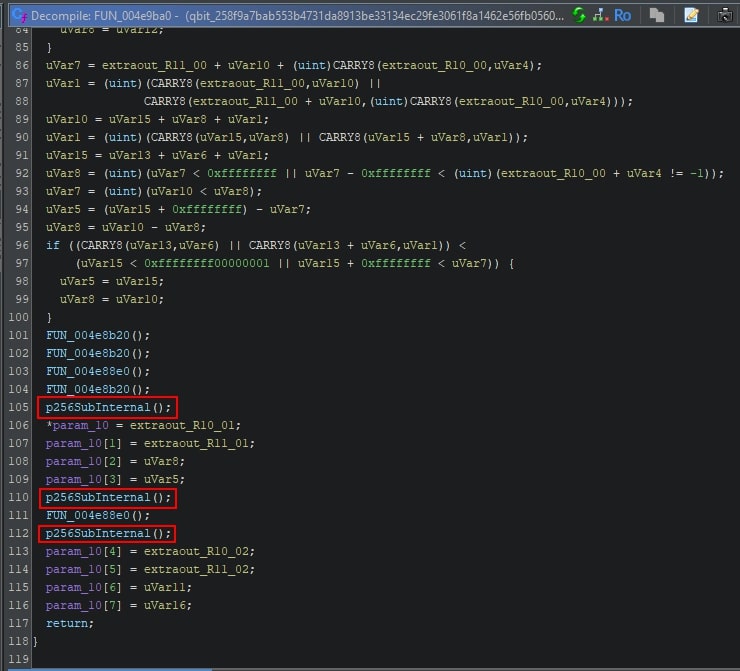
This provides more context when analyzing this function, as it provides tangible names to search for, along with context where the match originates from. The match information is based on the information provided when creating a FunctionID database. The image below shows the context provided by Ghidra for a FunctionID match.
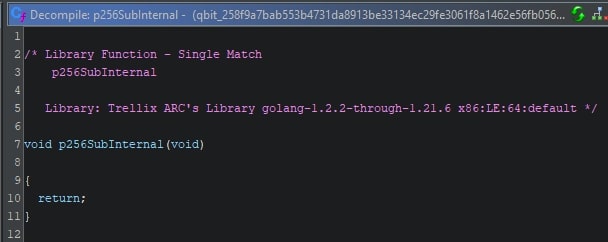
If the used runtime or library wasn’t known beforehand, one can now search for said code and learn more about its internals and/or usage in order to better understand the code at hand.
Maintaining a FunctionID database
Once a FunctionID database has been created, it can be used with future Ghidra instances to recognize functions in imported programs. Given the updates to Ghidra’s features over time, the programs within a Ghidra project can become outdated over time. When wanting to update a FunctionID database, one has to make the required changes by adding and/or removing programs in the project, after which the FIDB can be regenerated.
However, before generating a FunctionID database, one has to ensure that all programs within a Ghidra project are up-to-date. To iterate over all programs within a project, each program needs to be accessible. If a program is outdated, it is not accessible. Omitting programs which are outdated is possible but would limit the results, since only a subset of the programs within the project is used to generate the output.
Programs are not referencing the binary that has been imported into the Ghidra project, since it is not subject to change. Rather, the reference is to the LanguageID version, which refers to a SLEIGH mapping of the given binary type to Ghidra’s internal intermediate language called P-code, more on which below. In other words: the mapping of the assembly instructions for the given binary type are mapped to Ghidra’s internal intermediate language.
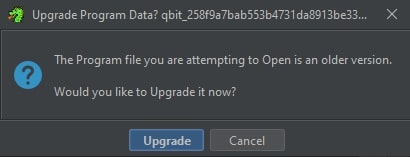
Over time, instructions can be added or altered in the SLEIGH mapping, potentially resulting in a different disassembly of the program. Programs can manually be upgraded when opened with a version of Ghidra which has a newer version than the program’s current version, as is shown in the image below. This is fine for small scale projects where a handful of binaries are analyzed.
When dealing with large projects, which include thousands of binaries, the manual approach is not an option. Ghidra’s development team has a solution for this with the help of a publicly available Ghidra script, named RepositoryFileUpgradeScript. It can be used when running Ghidra headless to upgrade all programs within a project. The script’s output when upgrading programs is shown in the image below.

BSim
Just before Christmas 2023, the NSA released BSim (short for “Behavioral Similarity”) for Ghidra. This feature is meant to compare a given number of functions from the current sample with a database of functions, and find similar functions. BSim uses Ghidra’s P-Code, which is its internal intermedia language, not to be confused with other types of P-Code. Before diving into BSim, a brief primer of P-Code follows
P-Code
Ghidra’s intermediate language allows all features to work based on a single language, making the communication between features easier and more efficient. Yet, Ghidra is capable of analyzing a plethora of different binary types. To do so, each binary type and architecture is mapped to P-Code using a SLEIGH specification which allows Ghidra to handle all mapped types and architectures. For the sake of simplicity, we will not dive into all the intricate P-Code details, but rather summarize the results in an understandable manner.
There is a difference between P-Code and High P-Code. Normal P-Code is an equivalent representation of the disassembled code. Essentially, one who understands P-Code, can read any type of disassembled code in Ghidra without the need to understand the architecture at hand. Knowing both is advantageous to identify and resolve mapping mistakes. The disassembly listing view allows one to view the P-Code if desired.
High P-Code, obtained via the decompiler feature, links segments of P-Code (VarNodes) to correlate read and write actions. To illustrate, High P-Code is what allows the decompiler to track variables within decompiled code. High P-Code is more useful, but is more costly to generate as relations within the code aren’t trivial to compute.
BSim signatures
Signatures for BSim are created based on the vectors within each function’s High P-Code. The calculated vectors of a function, along with their significance is stored in an XML-based signature, as shown in the excerpt below.

Within the signature file, information about the file from which it was derived is present. It also contains the path to the Ghidra project it came from as this is used to open said program in a side-by-side view when using BSim as intended. Each “fdesc” (function description) field contains information about the function name, its address, and the calculated vectors. The following “call” fields contain information about the calls within the function in question.
The significance of a function depends on several factors, one of which is size. Small functions tend to be harder to compare due to the lack of specifics and are often of lesser importance than larger functions. BSim signatures can then be imported within a supported database. Additional information on BSim can be found here.
Noteworthy is BSim’s optional approach to ignore specific values within the High P-Code’s VarNodes to allow a 64-bit signature to match a 32-bit function and vice versa. In some cases this tradeoff sacrifices some accuracy, since the sizes of certain values are truncated to avoid differentiating the different architectures (i.e. an integer is 4 bytes in a 32-bit architecture, while it is 8 bytes in a 64-bit architecture).
As long as access is retained to the Ghidra project to which the signature is linked, as well as the program within it, BSim allows one to view the decompiler output of said function from the original binary, as well as the current binary with which the match has been found. This is especially useful when reversing a function that has already been reversed in full, and only differs marginally. Think of it as having source code-esque access, if the previous analysis was thorough.
As with any feature within Ghidra, it is possible to interact with BSim via the graphical user interface and via scripts. BSim related Java objects have been abstracted where possible to allow for a more generic use, and to avoid (extensive) rewrites once parts of BSim are updated in the future. As such, the connection to a database is abstracted into a single object, even though BSim currently supports three different database types.
When searching for matches based on a given function, a similarity value will be defined. This value ranges between zero and one, where one is an identical match. Per search, one can specify a similarity threshold before a result is included in the returned match, along with a maximum number of matches per function, and a threshold for the significance for a given match. This allows one search more efficiently, as potential matches which do not meet the given prerequisites can be discarded immediately without wasting time on further checks for said functions.
Automatic BSim querying
Interaction with BSim is possible via the aforementioned Java objects and API. Each BSim signature contains vectors and some meta-data, while the exact decompiled code can only be found within the specific program within the referenced Ghidra project. As such, the conventional approach would be to ensure access to all relevant data. This would, however, limit the usability of BSim. The BSim script released in tandem with this blog can be found here.
There is but one drawback to recover function names in bulk with the help of BSim signatures from a local database without access to the original programs they were generated from: verification of the result. By searching for each non-default named function in a given program, querying each of those functions to one or more BSim databases, with a variable number of maximum number of matches per function, similarity, and significance, one can automatically rename functions which are identical matches.
Given how multiple matches can return a different name per match, it is also possible to rename functions generically. That is to say, if you have a known selection of function names which slightly differ in names (such as runtime related functions), they can be marked as such, without requiring the exact name to be known upfront.
A prime example of this is the Golang runtime. While some functions have been moved around in different packages, or the packages have been renamed, the vast majority of runtime related functions aren’t required to be named during the reversing, as long as their origin is marked as such.
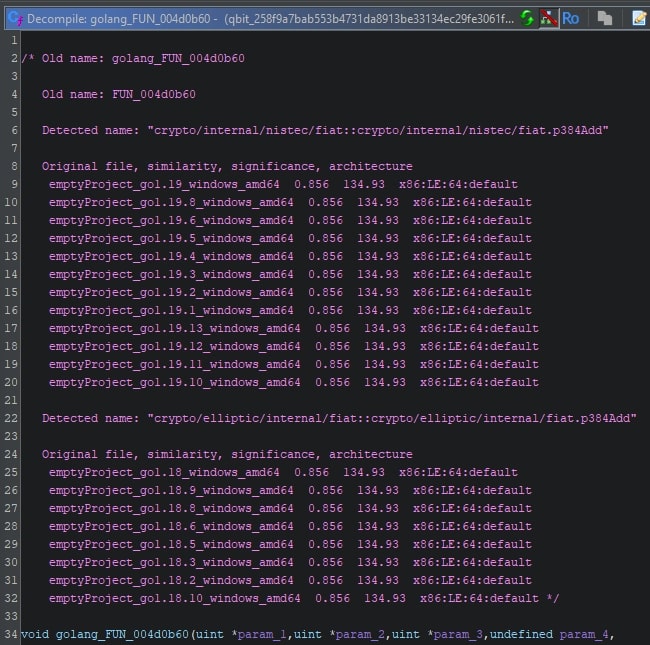
The runtime related functions which are called directly from library or user code would benefit from having function symbols. The BSim script accommodates this by offering the option to rename generic matching functions by prefixing a given string to it. The two recovered function names “crypto/internal/nistec/fiat::crypto/internal/nistec/fiat.p384Add” and “crypto/elliptic/internal/fiat::crypto/elliptic/internal/fiat.p384Add” do not seem to differ much at first glance. However, from a programmatic point of view the two names (treated as strings) aren’t identical, even when disregarding the casing. As such, these names conflict, and no verdict can be reached. Ignoring these two matches would be unwise, as they do meet the required similarity threshold. The solution is to prefix the function in the current program with the given prefix, which in this case is “golang”. This way, one can use different prefixes when using different BSim databases in sequence without overcomplicating the automatic querying script.
To retain the meta-data from the BSim matches, they are added as comments to the function, regardless if the generic renaming is enabled or not. The added comment does not only add the function name of the match, but also the original program’s name, similarity, significance, and LanguageID. These help the analyst to quickly make a decision during the manual analysis while remaining accurate.
In the case above, either of the two function names works, given that the similarity, significance, and LanguageID are identical. The more accurate name would be the one which matches the used Golang version in the sample, but this is not always known. The function’s purpose does not differ between the two versions, making the specific package it originates from less relevant.
There are cases where a function’s matches result in different function names where the function names themselves refer to an entirely different function. Knowing more about the sample (i.e. runtime version) can help to decide, and in some cases the context of the caller can lead one to a clearer understanding. This is, however, circumstantial, and since all occurrences are judged on a case-by-case basis, it does not always automatically provide the correct function name, even when matches are found. It does, however, provide tangible points to look into and base a decision on.
Much like the difference the FunctionID signatures made for a given Golang function, please refer to the same function in the screenshot below, where the post-FunctionID situation is shown.
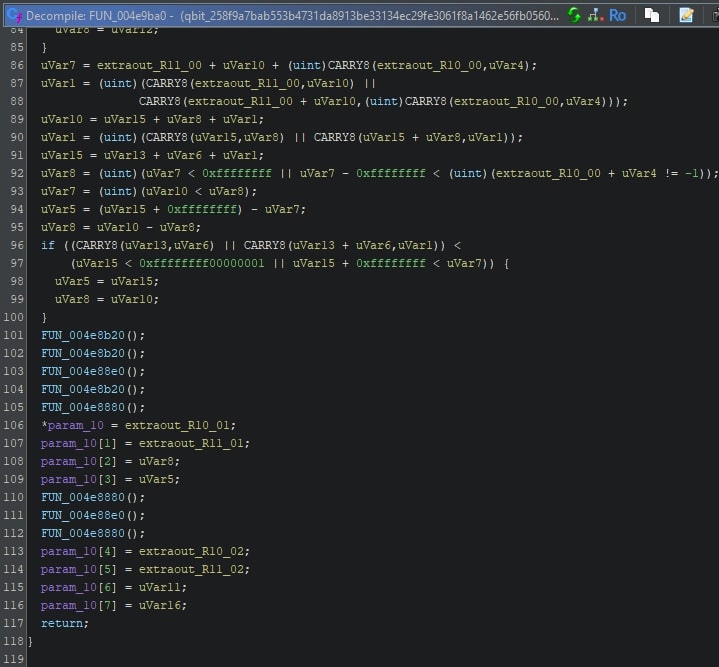
The two functions, FUN_004e8b20 and FUN_004e88e0, have not been identified yet. Using the BSim signatures for the 64-bit Windows Golang runtime with generic matching enabled in the rename script, they are both renamed.
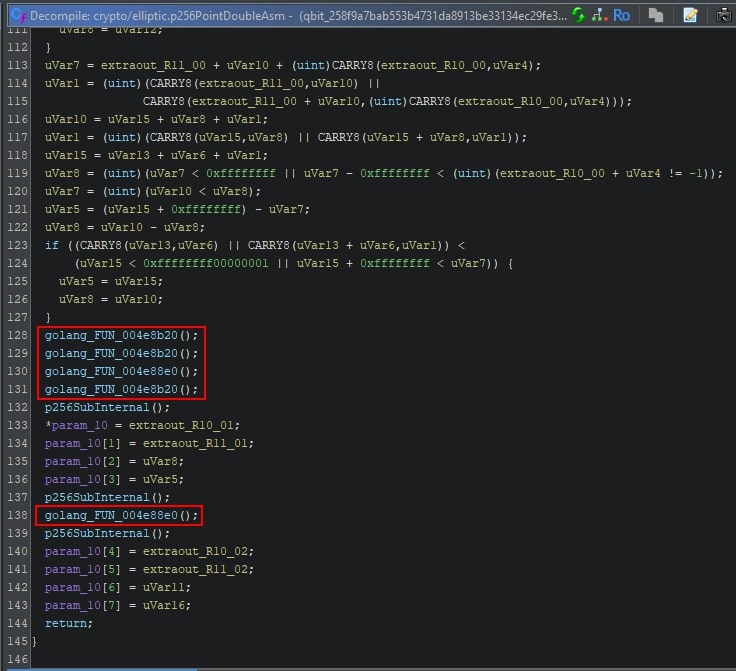
The “golang_” prefix is added to each of the generically matched functions. The comments added to each of these matches provide insight with regards to the potential function name.
Given that this BSim database only contains 64-bit Windows Golang runtime related signatures, the direct and generic function calls to Golang runtime related functions within this function likely indicate that this function is also part of the Golang runtime. Cross references of this function can help, but are not of much use in this specific example.
Bulk signature generation
Having discussed both FunctionID and BSim signature generation, and the release of scripts to aid in their generation, this leads to the testing of said scripts on benign binaries in bulk. This section contains the results of the generated FunctionID and BSim signatures, along with a deeper dive into the results where possible.
FunctionID results
Ghidra 11.1 (built on January the third 12:35 CET) has been used to generate all FunctionID databases within this blog. Using a different version might yield different results. Below, a detailed table is given to indicate the number of functions which Ghidra visited (iterated over), how many were added to the created FunctionID databases, and how many were excluded.
| Project name | Number of visited functions | Number of included functions (percentage of the total) | Number of excluded functions (percentage of the total) |
| Golang (first available version through 1.21) | 90,607,319 | 48,472,262 (53.5%) | 42,135,057 (46.5%) |
| Boost (1.65.0 through 1.84.0) | 72,103,526 | 28,191,439 (39.1%) | 43,912,087 (60.9%) |
| libxml2 | 3,086,400 | 1,608,164 (52.1%) | 1,478,236 (47.9%) |
| openssl | 1,756,157 | 818,210 (46.6%) | 937,947 (53.4%) |
| libgcrypt | 1,372,868 | 673,280 (49.0%) | 699,588 (51.0%) |
| libnettle | 900,231 | 447,443 (49.7%) | 452,788 (50.3%) |
| liblzma | 212,956 | 108,279 (50.8%) | 104,677 (49.2%) |
| msvc-empty | 325,379 | 86,479 (26.6%) | 238,900 (73.4%) |
| uclibc (from Enterprise Linux 7 and 8, and Ubuntu) | 76,355 | 47,394 (62.1%) | 28,961 (37.9%) |
| libzlib | 40,592 | 16,292 (40.1%) | 24,300 (59.9%) |
| libsodium (from Enterprise Linux 7 and 8m and Ubuntu) | 34,054 | 16,093 (47.3%) | 17,961 (52.7%) |
| avr-libc (from Enterprise Linux 7 and 8, and Ubuntu) | 33,944 | 15,616 (46.0%) | 18,328 (54.0%) |
| libbzip2 | 14,712 | 7,433 (50.5%) | 7,279 (49.5%) |
| Total | 170,564,493 | 80,508,384 (47.2%) | 90,056,109 (52.8%) |
Roughly half of all visited functions were eligible for, and have been included in, FunctionID databases. The excluded functions per project provide insight as to the reasons why roughly half of all visited functions were excluded. The table below provides the figures.
| Project name | Total number of excluded functions | Too short (percentage of the total) | No symbol (percentage of the total) | Duplicate (percentage of the total) | Thunk (percentage of the total) |
| Golang (first available version through 1.21) | 42,135,057 | 978,141 (2,3%) | 380,393 (0.9%) | 40,381,096 (95.8%) | 395,427 (0.9%) |
| Boost (1.65.0 through 1.84.0) | 43,912,087 | 9,281,079 (21.1%) | 16,105,146 (36.7%) | 17,825,264 (40.6%) | 700,598 (1.6%) |
| libxml2 | 1,478,236 | 57,108 (3.9%) | 308 (0.0%) | 1,409,087 (95.3%) | 11,733 (0.8%) |
| openssl | 937,947 | 208,071 (22.2%) | 29,655 (3.2%) | 661,923 (70.6%) | 38,298 (4.1%) |
| libgcrypt | 699,588 | 63,940 (9.1%) | 474 (0.1%) | 596,564 (85.3%) | 38,610 (5.5%) |
| libnettle | 452,788 | 28,982 (6.4%) | 5,706 (1.3%) | 410,223 (90.6%) | 7,877 (1.7%) |
| liblzma | 104,677 | 4,974 (4.8%) | 207 (0.2%) | 96,496 (92.2%) | 3,000 (2.9%) |
| msvc-empty | 238,900 | 9,552 (4.0%) | 163,578 (68.5%) | 57,955 (24.3%) | 7,815 (3.3%) |
| uclibc (from Enterprise Linux 7 and 8, and Ubuntu) | 28,961 | 2,802 (9.7%) | 12,337 (42.6%) | 13,230 (45.7%) | 590 (2.0%) |
| libzlib | 24,300 | 1,133 (4.7%) | 10,440 (43.0%) | 11,801 (48.6%) | 926 (3.8%) |
| libsodium (from Enterprise Linux 7 and 8m and Ubuntu) | 17,961 | 6,310 (35.1%) | 18 (0.1%) | 10,328 (57.5%) | 1,305 (7.3%) |
| avr-libc (from Enterprise Linux 7 and 8, and Ubuntu) | 18,328 | 2,245 (12.2%) | 1,785 (9.7%) | 12,315 (67.2%) | 1,983 (10.8%) |
| libbzip2 | 7,279 | 831 (11.4%) | 56 (0.8%) | 5685 (78.1%) | 707 (9.7%) |
| Total | 90,056,109 | 10,645,168 (11.8%) | 16,710,105 (18.6%) | 61,491,967 (68.3%) | 1,208,869 (1.3%) |
Note, all percentages have been rounded to the nearest decimal, meaning the total in the rows might not add up to 100%.
Out of all excluded functions, one makes up the vast majority: duplicate functions. At 68.3%, nearly seven out of ten functions seem to be duplicates. This is not an error in Ghidra’s FunctionID algorithm, but rather an expected result based on the used file corpus. For each project, numerous versions of the same runtime and/or library have been analysed. While different versions alter existing functions, and add or remove other functions, the majority of a runtime between different versions remains the same, especially when handling numerous minor version increases.
The Golang minor versions are the reason as to why more than 95% of the excluded functions are duplicates: the runtimes simply contain a lot of the same functions. The duplicate count for the analyzed Boost libraries is high due to the same reason, yet not as high. With these libraries, the large number of missing symbols seem to come from pointers to excluded functions within the binaries, causing a single missing symbol to inflate in its number (though as many references do exist within the libraries).
BSim results
For the BSim signatures, no specific numbers are available as Ghidra does not provide such output. Instead, the total uncompressed size of the generated signatures per project is used as a ballpark figure, in mebibyte (MiB) and rounded off to the first digit. All results have been generated with Ghidra 11.0.1 (built on January the 8th 17:27 CET).
| Project name |
BSim signature size in mebibytes |
| Golang (first available version through 1.21) |
70,713.5 |
| Boost (1.65.0 through 1.84.0) |
41,127.8 |
| 2654.9 |
|
| 1105.9 |
|
| 1197.8 |
|
| 613.0 |
|
| 175.6 |
|
| 147.3 |
|
| uclibc (from Enterprise Linux 7 and 8, and Ubuntu) |
62.8 |
| 44.6 |
|
| libsodium (from Enterprise Linux 7 and 8m and Ubuntu) |
18.1 |
| avr-libc (from Enterprise Linux 7 and 8, and Ubuntu) |
18.2 |
| 17.9 |
|
| Total |
117,897.4 |
The large file size for the signatures for Golang and Boost corresponds with the file corpus size, which is significantly larger than the file corpus size for the other projects. The signatures can contain duplicates, which are removed when inserted into a database of choice. Given the lack of numbers for this section, its usefulness and capabilities are best shown in a case study, as the next section shows.
Case study: qBit stealer
The above provides the required fundamental knowledge to create function signature databases based on an arbitrary set of binaries, and how to use the databases provided in tandem with this blog. To illustrate, the function symbol recovery of a stripped Golang binary will be outlined below. This sample is the qBit stealer with a corrupt program-counter line-number table (pclntab), meaning the metadata within the binary is unavailable and none of the function symbols can be recovered based on said corrupt metadata.
No symbols have been made for this specific sample. Instead, function symbols have been made for the Golang runtime. In this case, the Windows-based x86_64 Golang runtime databases are used, as they match the binary’s target operating system and architecture. For those wishing to follow along with the open-sourced material, the sample’s information is given below.
| qBit Stealer | |
| MD-5 | 374fb777ed62ebf0d9f16e7ec09139cf |
| SHA-1 | 706a79420bc79a39b6d98e1fa7fc1f242f79b594 |
| SHA-256 | 58df1e9c15c471c2048682e761ad8ef026bba47e9f81d66cb0eea6d2d716b34f |
| Detection names | FE_Ransomware_Go_qBit_1 FE_Ransomware_Go_qBit_2 FE_Trojan_Go_qBit_1 FE_Trojan_Go_qBit_2 qBit-Stealer.a trojan !!! Malware.Binary.exe |
When importing the file into Ghidra there are several options. Normally, the runtime type information (RTTI) for Golang binaries is wanted. This requires one to import the file under the “golang” compiler specification. In this case, it does not matter as much, since Ghidra’s internals use the same program-counter line-table as mentioned above, which this sample is lacking. As such, it can be imported under the “default” compiler specification as well, but it does not hurt to load it under the Golang specification.
Once the analysis from Ghidra has finished, one will be greeted with 2016 functions, out of which 2015 start with “FUN_” followed by the address the function starts at. This is Ghidra’s default naming scheme for functions which have no symbol within the binary nor in any of the connected function signature databases. The only other symbol at hand is called “entry” and is the binary’s entry point.
Once the database has been attached (see Appendix A), click “Analyze -> Auto Analyze ‘sampleName’” in the code browser or simply press “A” to display the auto-analysis options. Deselect all analyzers and enable the “Function ID” analyzer. The window, in the required state, is shown below.
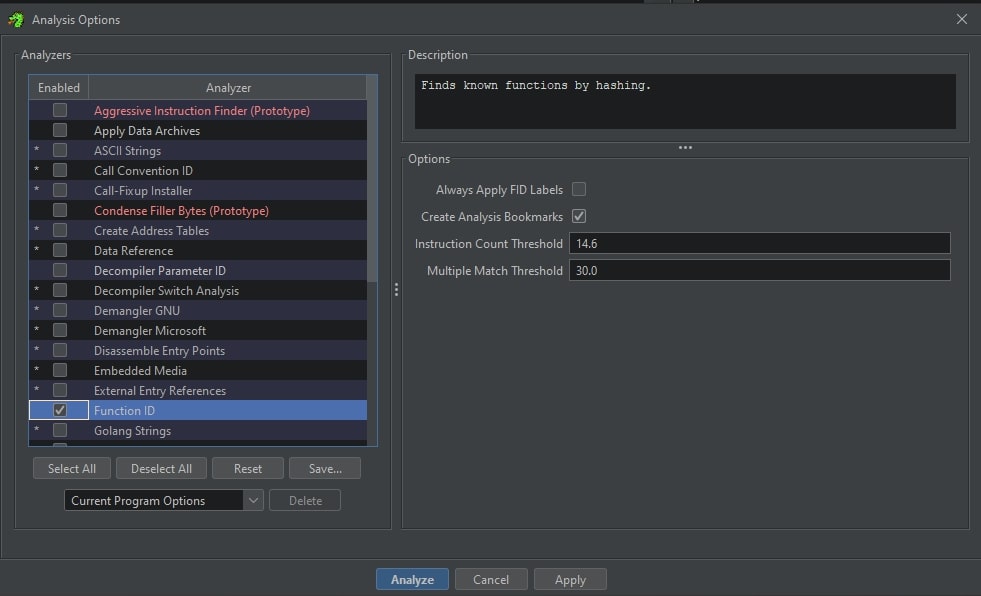
In the future, the newly attached FunctionID database will be queried automatically during the first analysis of a sample. In this case, the sample was already analyzed before the FunctionID database was attached, which was done to show the difference with and without the usage of the database during analysis.
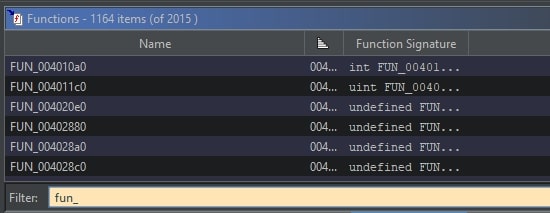
The total number of functions decreased by one, from 2016 to 2015, as one function got merged with another function. One function is named entry, leaving 2014 functions which contain “fun_” (case insensitive) in their name. The total number of renamed functions equals 2014 minus 1164, which is 850.This equals 42% of the total number of function symbols in the binary.
To further recover function symbols, BSim can be used. To use the graphical user interface for BSim, one has to ensure it is enabled within your instance in Ghidra by going to “File” and clicking on “Configure”. Within the newly opened window, check “BSim”, after which “BSim” should be visible within the Code Browser’s menu strip as an entry. One can attach and subsequently query a given BSim database for one or more functions within the current program. The script released with this blog does not utilize the graphical user interface, nor does it rely on databases connected with the Ghidra instance.
Run the BSim script named BsimFunctionRenamer and answer all questions that pop-up. These questions define the scope of the search, and the possible subsequent actions taken thereafter. When running Ghidra headless, these pop-up questions can be passed along as command-line arguments, ensuring the script can be used in either way. Do note that when providing the database location for a local database no file extension is to be provided. The local database uses two file extensions, none of which is to be included. When running the script with single, multi, and generic match renaming enabled, a similarity threshold of 0.7, a significance threshold of 0, and 20 maximum matches per local function, 319 additional functions are recovered. Put differently, this is a recovery of nearly 16% of the total function symbols.
In total 1169 function symbols (850 with the help of FunctionID signatures and 319 from the BSim database) have been recovered, all based on the Golang runtime signatures. This equals 58% of the functions within the binary. The leaked qBit source code does indeed show that the stealer’s code base is relatively small, compared to the embedded runtime related code. However, the user code within the binary is unlikely to make up 42% of all functions.
As defined earlier on in this blog, this is only one out of three types of code. The library and user code are still undefined. To recover the library code, one would have to find the libraries used within the binary, if any. Without symbols, some specific strings might stand out and lead to the detection of a binary, as would very specific functionality, sheer luck, or experience. There is no tried-and-tested recipe to find any or all libraries within a binary.
An example of a string which might be of interest could be “<MouseLeft>”, as it’s not a common string. This example has been taken based on the Systernals strings tool’s output, as Ghidra does not recognize it as a string within the strings view post analysis. Searching for this literal string on a search engine with “golang” next to it will show a fork of the project as one of the top hits, while the search result also shows the string being used as a string literal within the code. This could be the starting point when looking for a library, but it is a time-consuming process which usually does not yield a (complete) positive outcome.
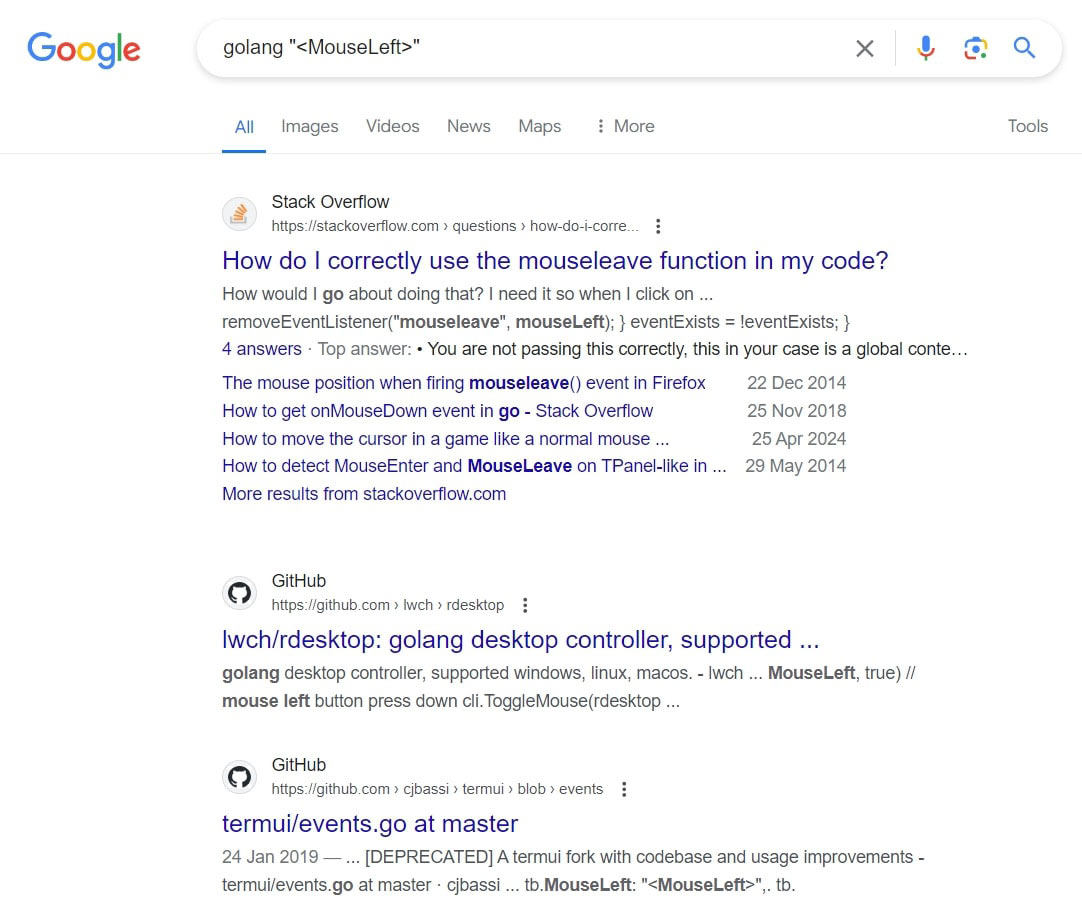
The released databases only cover the Golang runtime, no Golang libraries. With the provided script, it is possible to generate signatures for libraries that are interesting, within a short timeframe. This decreases the required time spent once a matching library is found but does not decrease the time spent when looking for said library. Also note how some libraries embed other libraries within them, further complicating the search, as one might find strings belonging to an embedded library. This would result in some recovered symbols, but not in a complete match of the libraries at hand. Some symbols are better than none, but it is difficult to find out if all library code has been identified without access to the original source code, which is not present in the majority of all cases.
This example is based on a sample from which the source code is available, to best explain the process itself. When looking at the leaked source code of the qBit stealer, it becomes apparent which benign library has been used: Zack ‘gizak’ Guo’s termui. To avoid confusion: the library itself is not affiliated with the stealer in any way. If one were to compile a binary with this library and generate FunctionID and BSim signatures for it, even more function signatures could be recovered.
Assuming signatures for the above-mentioned libraries would be generated and applied, and accepting that both techniques will not recognise all functions, the majority of the leftover functions which aren’t too small to be reliably detected should be user code. With the help of renamed runtime and library code, reversing the user code is now a much more efficient and less time-consuming process.
One notable drawback is the lack of detection for undefined functions. Both techniques rely on Ghidra to identify a function at a given location, where experience with Golang reversing shows that the pclntab recovery method significantly increases the number of functions Ghidra defines within a binary. Any function which is manually defined at a later stage can be put through the same process to potentially identify it. The aggressive instruction scanner analyzer within Ghidra can be of use, depending on the use-case, but it is also prone to false positives. As such, it is advised to only be used sparsely.
All in all, the analysis of the qBit sample is now feasible due to the recovered function names, especially if more symbols for the found libraries were to be generated. The original situation had no defined function names, making the process infeasible as the reversing process would consume too much time.
Methodology
The theory outlined above, as well as the given case study, provides a practical example of the methodology. More simply put, this workflow consists of three fundamental steps one can apply when analyzing a binary. The flowchart below summarizes the workflow, which is explained in detail afterwards.
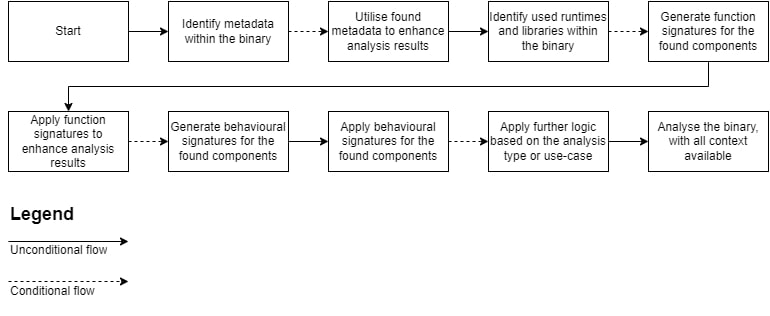
The first step is the usage of metadata within a binary. As mentioned before, Golang’s “pclntab” allows one to recover function names from stripped binaries. Such metadata is, however, not always present within binaries. A stripped C++ binary does not contain such data. As such, the step is conditional, as it depends on the type of binary.
Next, one has to identify the used code types and generate function signatures for said code types. More practically put: one has to create FunctionID databases for the used runtimes, libraries, and whenever possible user code. Once these databases have been created, they can be applied to the binary at hand. If such databases were already created in the past, they can be reused, assuming the code type’s version in the given binary is included in said database.
Thirdly, one has to generate and apply behavioral signatures for the code types in the binary. In this context, behavioral signatures are BSim signatures. It is important to only apply BSim signatures once the FunctionID signatures have been applied to the binary, since this use-case is not BSim’s intended purpose, but rather a shoehorned version of it. The FunctionID signatures are more reliable and match more functions than the shoehorned BSim script does, hence the required order.
Even though the methodology only mentions three steps, there is a fourth step, albeit up to the analyst’s discretion: applying additional scripts to the binary prior to reviewing the automated analysis manually. Given Ghidra’s flexibility, one can perform arbitrary actions to enhance the analysis results, using both public and proprietary (in-house) services. More context on this is given in the next section.
Future work
When running Ghidra headless, one can run the BSim querying script to automatically rename functions based on matches as a post script. Since one can run multiple scripts (including logic to only run certain scripts if specific criteria are met), this opens Ghidra’s analysis capability to include advanced additional analysers.
To illustrate, one could use a given large language model (LLM) to suggest meaningful names for default named functions (i.e. FUN_address in Ghidra). At REcon 2024, Emproof’s Tim Blazytko and Moritz Schloegel talk “The Future of Reverse Engineering with Large Language Models” showed that additional context within decompiled code improves the output, especially when starting at the bottom of a call graph, since childless nodes do not link to other (unknown) functions. Using the BSim function renaming script prior to using an LLM to further annotate functions within a binary would be helpful to provide more context.
Alternatively, or additionally, one can create and use FunctionID and BSim databases with specific purposes. One example would be to recognise runtime and library code at large, saving the analyst time. Alternatively, one can create and use such databases filled only with functions from malware, classified per family or malware type. As such, any hit would potentially indicate the sample’s family. The latter type of databases would require diligent filtering and removal of runtime and library related code to avoid false positives.
Last, the addition of more runtime and library related code to the current signatures are a goal on its own. This would allow more signatures to be created to further help analysts.
Conclusion
Understanding fundamental concepts with regards to the internals of binaries, as well as the internals of analysis frameworks (such as Ghidra), is vital to further enhance function symbol recovery techniques. It requires one to prepare upfront, by creating databases with various types of function signatures. The preparation is a continuous cycle since both benign and malicious software is developed continuously. Not generating new signatures will inevitably result in a lack of visibility at a later stage.
During the analysis, one can use the prepared signatures, and see if more can be done to recover function symbols from the binary at hand, such as the aforementioned Golang example where the program-counter line-table (pclntab) is of help. Such opportunities also require research upfront, as it generally takes too long to perform such research when opening a malware sample.
This blog focused on the why and how of signature generation for two Ghidra features: FunctionID and BSim. Generically speaking, other techniques are likely to function similarly, but specifics are bound to differ.
As a community, we can advance the technology and raise the bar for attackers, and I hope this contribution helps, even if it is only ever so slightly
This document and the information contained herein describes computer security research for educational purposes only and the convenience of Trellix customers.
Appendix A - Attaching a FunctionID database
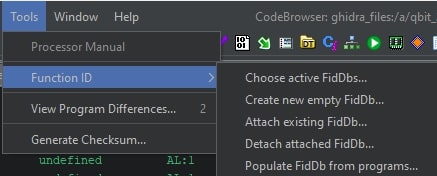
Ghidra allows one to create function signatures from any already analyzed program. This can be done from the graphical user interface by creating an empty FIDB file, populating it, and attaching it as shown in the high level overview from Ghidra’s CodeBrowser’s toolstrip menu in the picture below. One first has to create a new empty FIDB, after which it can be populated.
Once populated, it can be attached, which is when Ghidra can use it with the help of the FunctionID analyzer. The image below, taken from Ghidra’s CodeBrowser, shows the attach option by clicking on “Tools” -> “FunctionID” -> “Attach existing FidDb…”.
Once the desired FIDBs have been attached, one can verify if they are in-use within Ghidra with the help of the “Choose active FidDbs…” menu item. The dialog which then opens will allow one to (un)check a given FIDB file. In the image below, the Trellix Golang FIDB file for x86_64 is listed and attached, as can be seen based on the check mark in front.

Alternatively, this can also be done with the help of Ghidra’s FlatAPI and FunctionID related services. These can be executed via scripts, when running Ghidra with the graphical user interface or when executing it headlessly. Relevant code can be found in the published FunctionID generation script.
RECENT NEWS
-
May 19, 2026
Trellix Appoints Joe Chen as Chief Technology Officer
-
Apr 08, 2026
Trellix prevents enterprise data exposure in sanctioned and shadow AI
-
Mar 02, 2026
Trellix strengthens executive leadership team to accelerate cyber resilience vision
-
Feb 10, 2026
Trellix SecondSight actionable threat hunting strengthens cyber resilience
-
Dec 16, 2025
Trellix NDR Strengthens OT-IT Security Convergence
RECENT STORIES
Latest from our newsroom
Get the latest
Stay up to date with the latest cybersecurity trends, best practices, security vulnerabilities, and so much more.
Zero spam. Unsubscribe at any time.