Blogs
The latest cybersecurity trends, best practices, security vulnerabilities, and more

AIOps - Revolutionizing Incident Management with Advanced Automation and LLM Integration
By Trellix · November 14, 2024
Contributed by Chalapathy Jampal, Siddhesh Shinde, Alagiri Annadurai, Lakshmi Ram Teja Eluri and Anil Pokhrel
Managing infrastructure and applications across a complex IT landscape has become increasingly challenging in today's fast-paced digital environment. Enterprises are expected to maintain high availability and reliability across multiple cloud environments and diverse application architectures. However, with this complexity comes a range of challenges, including:
- Alert Fatigue: With multiple monitoring tools generating alerts, IT teams often face an overwhelming volume of notifications, many of which may be redundant or low-priority, leading to alert fatigue and missed critical issues.
- Fragmented Incident Management: Disparate systems and tools often result in fragmented incident management processes, making it challenging to correlate alerts and track incidents efficiently across different platforms.
- Manual Resolution Efforts: A significant amount of time and resources is spent on manually investigating and resolving incidents, particularly for Level 1 and Level 2 support, leading to increased costs and slower response times.
- Lack of Contextual Insights: Alerts often lack the necessary context to quickly identify root causes and impacted services, leading to delays in incident resolution.
- Scalability Issues: As infrastructure and applications scale, the traditional manual approaches to incident management become increasingly unsustainable, requiring more automated and intelligent solutions.
This is where AIOps comes into play, leveraging AI/ML to automate IT operations and ensure seamless incident management. While Trellix is focused on improving cybersecurity products using LLM and GenAI, we have developed this AIOps tool to enhance our internal IT operations. By automating Level 1 and Level 2 support for applications, this tool aims to significantly reduce COGS, boost efficiency, and enhance overall performance.
In this blog, we’ll delve into how our AIOps system integrates alerts from various monitoring tools, enriches incidents using a graph database, integrates with IT Service Management (ITSM) tools like JIRA, and automates resolution workflows using the Workflow automation engine.
Integrating Alerts from Multiple Sources
Our AIOps platform brings together alerts from several industry-leading monitoring tools:
- PagerDuty: Incident response platform that helps manage and respond to incidents in real-time.
- Grafana: Monitoring and observability, for alert creation, monitoring dashboard.
- AWS CloudWatch: Monitoring and management service for AWS cloud resources and applications.
- GCP Cloud Monitoring: Monitoring service for tracking metrics, events, and metadata within GCP.
- Wiz: Provides cloud security, deep visibility and context for cloud environments.
These tools generate alerts based on various metrics, thresholds, and security events. However, managing these alerts in isolation can lead to alert fatigue and inefficiencies in incident resolution. Our AIOps system overcomes this by correlating these alerts using advanced AI/ML techniques.
Correlating Alerts with LLM/GenAI and Hierarchical Correlation
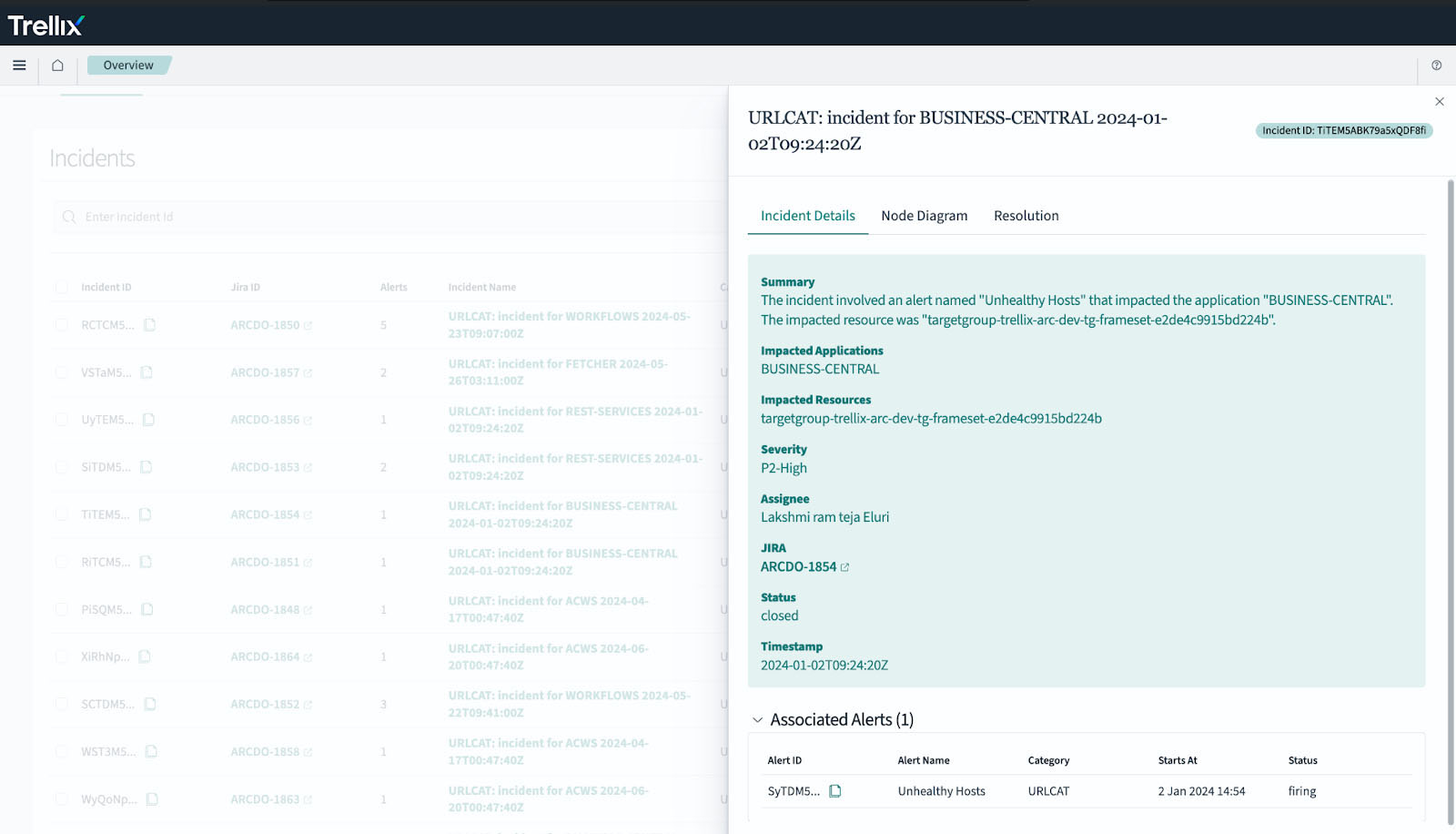
The key to effective incident management in our AIOps is linking related alerts into one manageable incident. Our AIOps architecture uses advanced AI and machine learning to analyze alerts, find patterns, and group them together. This goes beyond just matching keywords; it understands the context to connect alerts that might seem unrelated but are actually part of the same problem.
In addition to contextual correlation, the system also performs hierarchical-based correlation using application node architecture details stored in the graph database. This approach leverages the hierarchical relationships between different components of the application stack to identify and correlate alerts that are part of a cascading or multi-tier issue. By understanding the dependencies and architecture of the application, the system can more accurately correlate alerts that impact multiple layers of the infrastructure, providing a more comprehensive view of the incident.
Enriching Alerts and Incidents
Once an incident is created, it needs to be enriched with additional information to aid in quick resolution. Our AIOps system queries a graph database that holds the entire node-wise architecture of the applications. This database allows us to:
- Identify Impacted Nodes and Services: By understanding the relationships between different components of the infrastructure, we can pinpoint which nodes or services are impacted by the alerts.
- Determine Severity and Priority: The system analyzes the alert data to assign severity and priority levels to the incident, ensuring that critical issues are addressed first.
- Correlate Related Information: The system enriches the incident with details about the alerts, reasons for their correlation, and other contextual data.
- Assignee Details: Integration with Confluence allows the system to automatically assign incidents to the right teams or individuals based on their schedule and expertise.
- Root Cause Analysis and Resolution Recommendations: Using the enriched data, the system can provide insights into the root cause of the incident and suggest possible resolutions.
ITSM Tool Integration for Better Incident Management
- Scenario 1: When a ticket is created in Jira, the AIOps platform understands the intent of the ticket and triggers the appropriate workflow within the Workflow automation engine to resolve the incident. The platform records the resolution process and closes the ticket automatically, without any manual intervention.
- Scenario 2: If no automatic resolution workflow is set up, the AIOps tool assigns the ticket to the appropriate team based on its severity. It also provides detailed resolution steps to ensure the incident is handled efficiently.
This integration helps resolve incidents quickly and effectively, reducing downtime and improving service quality.
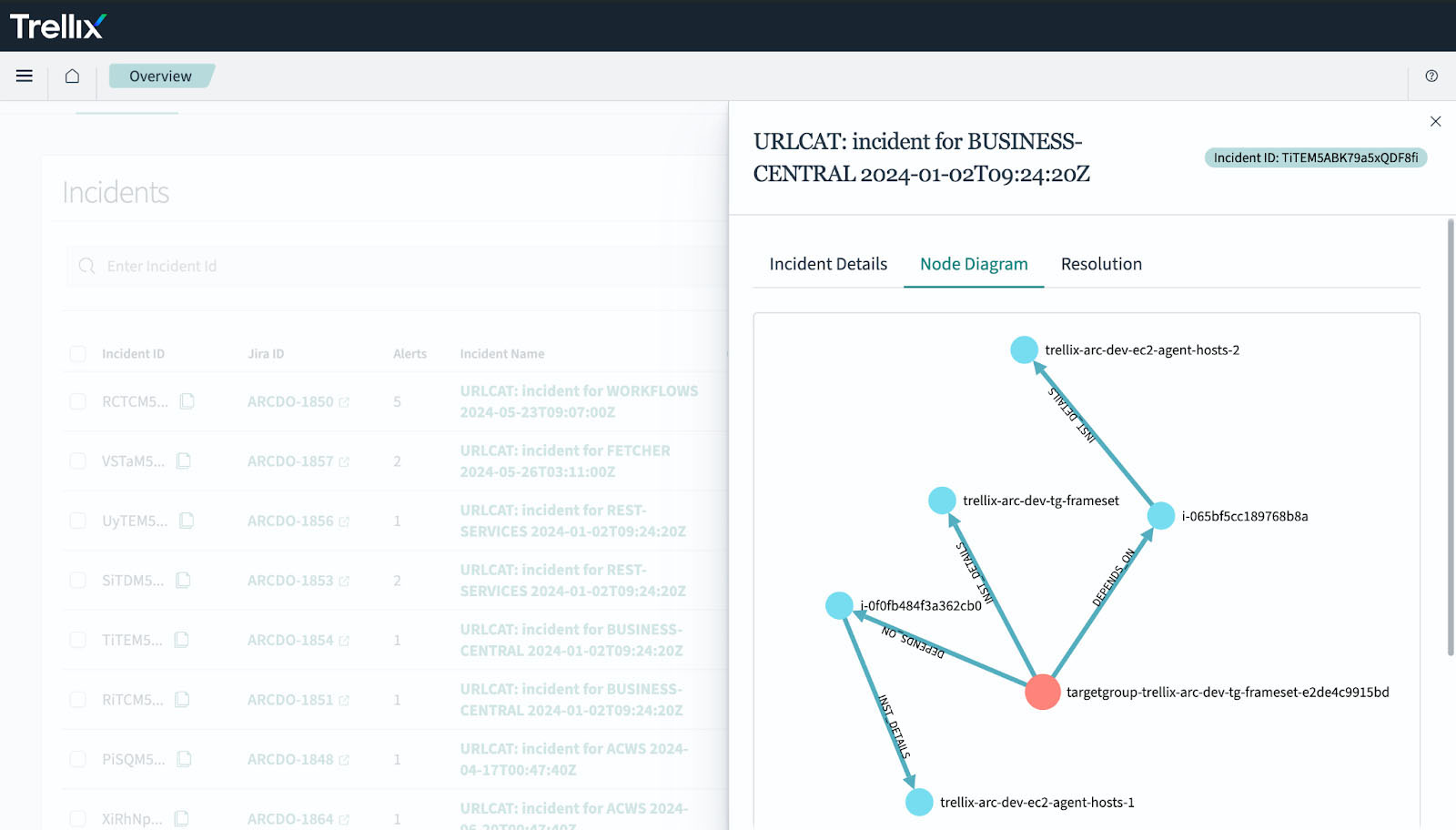
Visualizing Impacted Nodes
To provide a clearer understanding of the incident’s impact, our AIOps platform includes a visualization tool that displays the node diagram of the affected architecture. This visual representation helps teams quickly identify problem areas and assess the scope of the incident.
Automating Resolution Workflows with Workflow Engine
The AIOps platform is integrated with the Workflow automation engine, a versatile tool for running resolution workflows. This engine supports various types of automation, including:
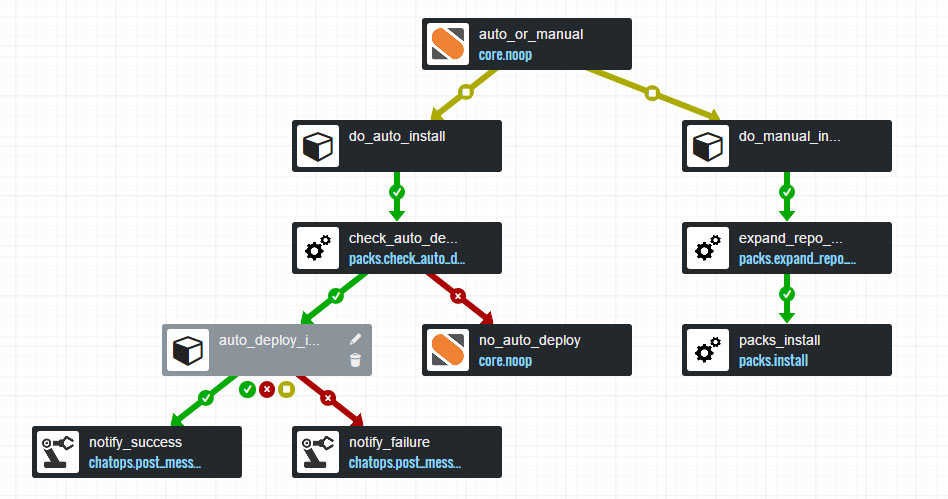
- Infrastructure Automation: Automating tasks such as scaling, provisioning, and configuration management to maintain optimal performance and availability.
- Configuration Automation: Ensuring systems are configured correctly and consistently across environments to prevent configuration-related incidents.
- Service Provisioning: Automating the deployment and management of services across cloud and on-premises environments to ensure seamless service availability.
- DevOps Automation: Streamlining CI/CD pipelines, monitoring, and other DevOps tasks to quickly address and resolve development and operational issues.
- Incident Management Automation: Automatically detecting, diagnosing, and resolving issues, including restarting services and managing incident responses efficiently.
The Workflow automation engine can execute scripts in multiple languages, including Bash, Shell, Python, and PowerShell, allowing for highly customizable and flexible automation processes.
Automated Incident Management Workflow in AIOps
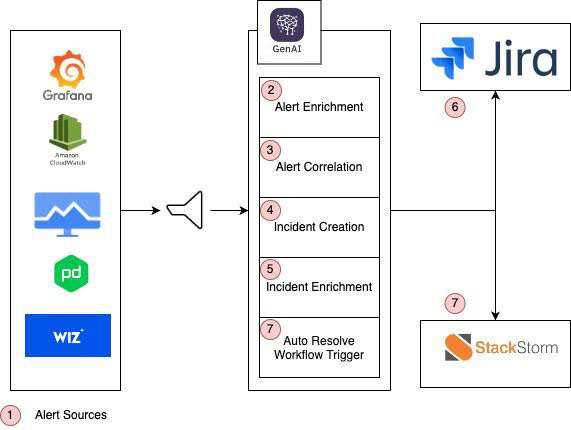
This diagram outlines the flow of an AIOps (Artificial Intelligence for IT Operations) system that integrates various alert sources and automates incident management using GenAI and other tools like Jira and StackStorm. Below is an explanation of the flow corresponding to the numbered steps in the diagram:
- Alert Sources:
The first step involves gathering alerts from various monitoring tools such as Grafana, Amazon CloudWatch, PagerDuty, GCP Cloud Monitoring, and Wiz. These tools monitor different aspects of the IT environment, including performance, security, and infrastructure. - Alert Enrichment:
Once alerts are received, they go through an enrichment process. This involves querying a graph database containing detailed information about the architecture of the monitored applications. The enrichment process adds valuable context to the alerts, such as the severity, impacted nodes/services, correlation reasons, assignee details, root cause, and resolution recommendations. - Alert Correlation:
The enriched alerts are then correlated using GenAI. This step is crucial as it helps in identifying patterns and relationships between different alerts, allowing the system to consolidate related alerts into a single incident. This reduces alert noise and focuses on the actual issues. - Incident Creation:
After correlation, an incident is created based on the correlated alerts. This incident represents a concrete issue that needs to be addressed, and it will be tracked and managed through an ITSM (IT Service Management) tool. - Incident Enrichment:
The created incident is further enriched with additional context, which might include deeper analysis, further details on impacted services, and actionable insights. This step ensures that the incident is well-documented and ready for resolution. - Incident Management in Jira:
The enriched incident is then pushed to Jira, where it is logged as a ticket. Jira serves as the ITSM tool where the incident will be managed, tracked, and assigned to the appropriate team for resolution. - Auto Resolve Workflow Trigger:
If a resolution workflow is available in StackStorm, the system can automatically trigger this workflow to resolve the issue. StackStorm is used to automate various tasks, including infrastructure automation, configuration management, and service provisioning. The system can either manually or automatically run these workflows, resolve the issue, and then close the Jira ticket.
In summary, the diagram represents an end-to-end automated incident management process, where alerts are collected, enriched, correlated, and transformed into incidents. These incidents are managed in Jira, and where possible, automatically resolved using StackStorm workflows, streamlining the entire IT operations process.
Conclusion
Our AIOps platform represents a significant advancement in IT operations management by combining the power of LLM/GenAI, hierarchical-based correlation, graph databases, ITSM integration, and Workflow automation engines. By correlating alerts, enriching incidents, integrating with JIRA, and automating resolutions, we reduce MTTR, enhance operational efficiency, and ensure that critical infrastructure remains resilient and available.
As we continue to evolve our AIOps capabilities, we invite teams across the company to explore the platform and leverage its full potential in maintaining and optimizing our IT environments.
RECENT NEWS
-
May 19, 2026
Trellix Appoints Joe Chen as Chief Technology Officer
-
Apr 08, 2026
Trellix prevents enterprise data exposure in sanctioned and shadow AI
-
Mar 02, 2026
Trellix strengthens executive leadership team to accelerate cyber resilience vision
-
Feb 10, 2026
Trellix SecondSight actionable threat hunting strengthens cyber resilience
-
Dec 16, 2025
Trellix NDR Strengthens OT-IT Security Convergence
RECENT STORIES
Latest from our newsroom
Get the latest
Stay up to date with the latest cybersecurity trends, best practices, security vulnerabilities, and so much more.
Zero spam. Unsubscribe at any time.