Blogs
The latest cybersecurity trends, best practices, security vulnerabilities, and more

Feeding Gophers to Ghidra
By Trellix · June 6, 2023
This blog was written by Max Kersten
The scripts discussed in the article are based on the magnificent work of Dorka Palotay from CUJOai.
Golang malware is becoming increasingly prevalent, requiring analysts to know how to effectively analyze these files without diving into a myriad of rabbit holes. This blog describes several Ghidra scripts to more easily and accurately analyze Golang binaries, significantly shortening the time an analyst spends on such binaries. Recently, the NSA has published Ghidra 10.3, which contains initial support for Golang 1.18. These scripts have support for more versions Golang versions, as well as a wider scope, such as the inclusion of ELF files.
The NSA’s free and open-source Ghidra is a widely adopted and industry standard analysis tool with which defenders can effectively collaborate by finding ways to improve the tool as a whole for everybody, while also imposing costs on attackers.
Trellix is a strong proponent of supporting and contributing to community projects when possible. Sharing these Ghidra scripts with the community proves that we practice what we preach: living security. This blog documents our journey of feeding Gophers to Ghidra, eventually resulting in multiple Java-based helper scripts (not to be misunderstood as JavaScript scripts).
To be clear: no Gophers were harmed during this research.
The start of the journey
In April 2022 in Nantes, France, at the 9th edition of Botconf, Dorka Palotay gave a presentation on Golang research in which her colleague György Lupták dove into the Sysrv mining botnet. The Ghidra scripts Dorka created can recover static and dynamic strings, functions along with their original names, and Golang types. These scripts were written in Python 2, which Ghidra executes via the Jython interpreter. Our team discussed Dorka’s research and wanted to expand upon it. The original scripts were unable to resolve all the issues one has when dealing with Golang binaries, and we felt we could improve upon Dorka’s foundational work to be even more useful for researchers.
Meeting the gophers
To fully understand how to analyse Golang binaries, proficiency in the language itself is paramount. The Golang source code, as well two notable blogs written by Dorka, were the foundation to understanding Golang internals.
The active development of Golang is bound to eventually break the scripts in minor (and potentially major) ways, which is why Golang version detection has been an area of focus. This allows the scripts to use a version-specific approach when necessary. Different architectures (i.e., Intel or ARM) as well as different versions of architectures (i.e., x86 and x86_64) each require a different approach, which is also handled granularly.
Understanding Ghidra’s internals
To extend Ghidra, one can write a loader, analyzer, or script. To (over) simplify for the scope of this blog, a loader is used to load binaries, while an analyzer and a script are both used after the binary is loaded. An analyzer can run at any time during the (auto-) analysis, while a script is invoked by the user at a specific moment in time.
Additionally, Ghidra uses P-code, which is a universal language that is used internally. Each supported architecture is mapped to P-code, after which the internal tools, such as the decompiler, utilize the P-code. This allows the decompiler to work for any supported architecture without further changes. It is important to note that there are two types of P-code: normal and high. Normal P-code contains all information, but is more difficult to traverse, while high P-code is more easily traversable while still containing all required information. The decompiler uses high P-code, which is how variables and code are linked together, although there is more to this than meets the eye.
The original work by Dorka resulted in four scripts. Reviewing Dorka’s work, there was no advantage in changing the number of scripts nor its format. A loader would be overkill, since the original loaders are already suitable. An analyzer or script wouldn’t make a difference, other than the portability of a script over an analyzer, since these are compiled during runtime, unlike the precompiled analyzers. In addition, analyzers are often version-bound, even if no breaking changes are present, and require a version bump and recompiling to work again.
As such, the superior portability is a useful advantage, while there are no real disadvantages. To facilitate the execution of all four scripts, a fifth script was created: a wrapper which calls the other four scripts sequentially. Even though it is possible to change some parts of the scripts to utilize Ghidra’s high P-code, and thereby work independently for any architecture, this hasn’t been done since Ghidra’s (high) P-code, and the up- and downsides thereof, were unknown. This is a potential improvement in a future update.
Feeding the dragon
With a basic understanding of Golang’s internals, the porting of the scripts into Java began. Barring some quirks, this didn’t take long. Once completed, it was time to enhance the scripts. Additionally, the script’s documentation had to be written in full. The focus on documentation ensured a proper understanding prior to making code changes. Given the easy-to-understand layout and concepts, one can trivially edit the scripts, be it for Golang or similar purposes.
Once the Java-based scripts were completed, and the documentation finished, the code base was refined. The original code wasn’t too efficient in some cases, and some edge cases were missing. Both aspects have been revised and refined, ensuring a faster and more effective outcome.
The testing was initially done with the Golang samples that Dorka referenced in her blogs, and then transitioned to other samples that our team encountered in the wild. The team highlights two such samples below as demo data, dating back to late January and early February 2023, which ESET attributed to Sandworm, and Symantec linked to UAC-0056. Below, hashes for the files are conveyed in multiple formats. Note that the Trellix product suite detects these files with the names shown in the “Detection names” row.
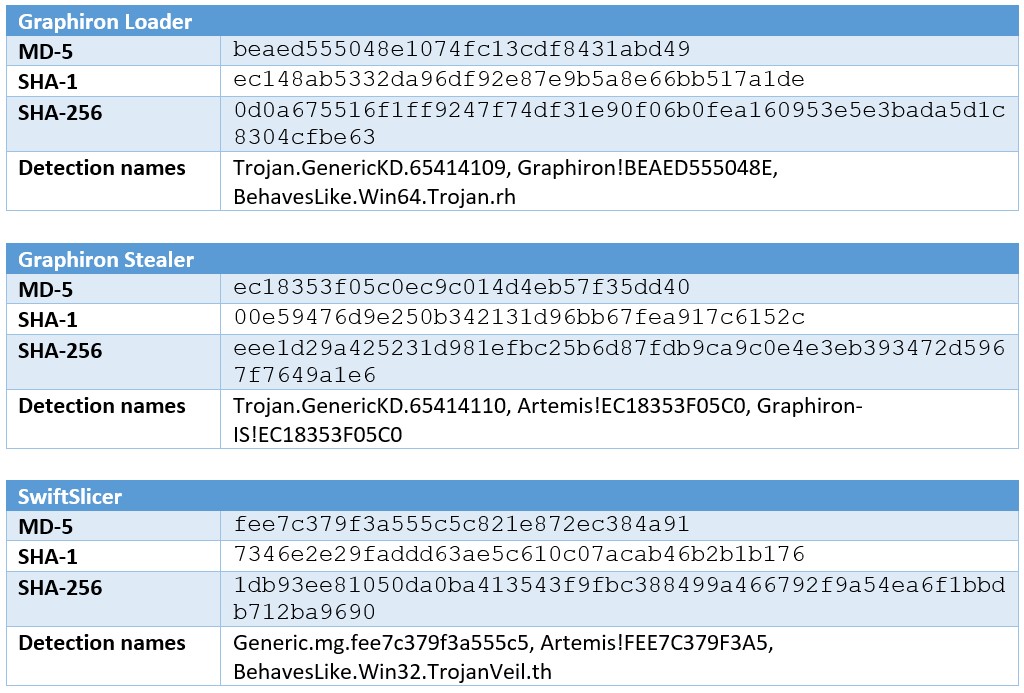
Based on Ghidra’s active development, it’s important to note that newer versions contain bug fixes and new features. While testing, we used Ghidra version 10.2-DEV, which was built from the public Ghidra sources available as of the 22nd of September 2022.
The figures below might vary when using a different Ghidra version, depending on the new features that were added and/or updated since. Regardless, they should demonstrate how these scripts enhance the analysis of Golang binaries. Prior to the execution of the scripts, all analyzers were selected with the “Select All” button.
Having verified the Ghidra version, the samples, and the used Ghidra analyzers, the results from the scripts can be interpreted. The following table shows the difference the execution of the scripts makes, for each of the three aforementioned samples.
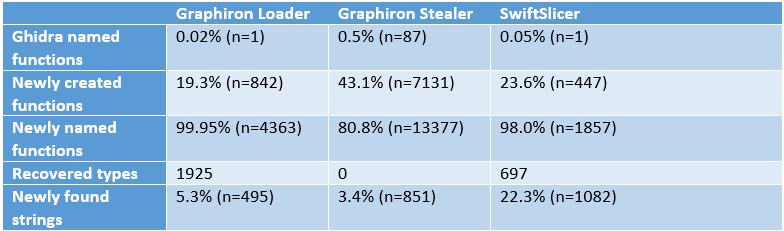
A brief explanation is required for this table’s values, to ensure the results are interpreted correctly. All percentages are based on the number of functions or strings in Ghidra once the scripts completed their execution.
“Ghidra named functions” are defined as the total number of functions that Ghidra finds after the aforementioned automatic analysis, excluding any function that starts with “FUN_” or “thunk_”.
The “Newly created functions’” value represents the number of functions that the function recovery script creates. Similarly, the “Newly found strings” are the number of strings created by the string recovery scripts.
The “Newly named functions” are the functions not named “FUN_” or “thunk_”, and are instead given a meaningful name to expedite the analysis of the code. Due to the recovery process, this value represents nearly a complete recovery of the original function names, even when the binary is stripped, which these binaries are. Ghidra currently does not contain a Function ID database for Golang functions, and even if it did, the user-generated functions would not be recovered, while this method is capable of doing so.
The recovered types are given as an absolute value, as there’s no comparison possible with the previously identified types, which can easily contain inaccurate results.
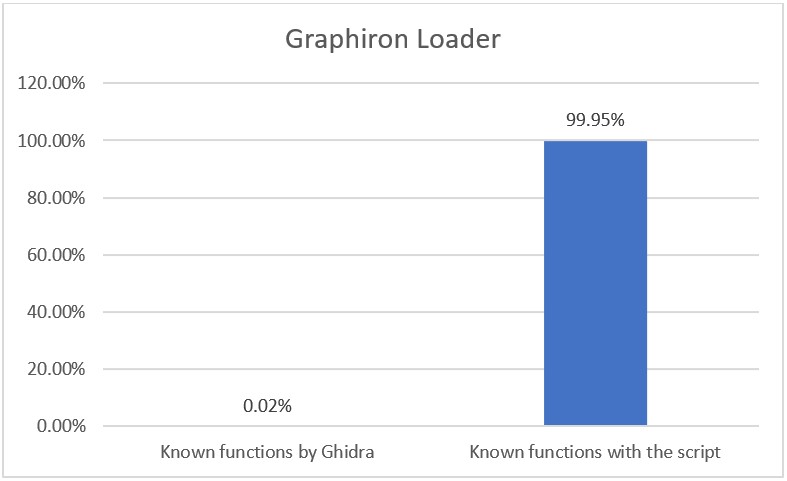
To illustrate the differences, the following graph compares the “Ghidra named functions” and the “Newly named functions”.
To see the difference between the default analysis of Ghidra and the result once the scripts have been executed, refer to the figure below. On the left is the original analysis, and on the right is the output once the scripts have been executed. The previously unrecognized functions (those starting with “FUN_” and “thunk_”) are renamed to their original names including the Golang package they originate from. This is done for both library code (such as the “os/exec.Command” function), as well as user-written code (such as “main.walkFunc”).
Library function recovery is also possible with function signatures, although this is not a suitable alternative as it would require dozens of signatures per function, due to code changes over time. Additionally, it wouldn’t allow the recovery of file names in user-written functions. Essentially, this allows one to analyze Golang files as if symbols were initially present.

The figure above shows that the first line in the screenshot changes the first argument of the function, from an unknown data type (marked as “DAT_”) to a recognized string with the correct length. This is the effect of the string recovery scripts, which allows Ghidra to display the data in its correct type. It now requires no clicks to understand that a WMIC command is executed in the first line, whereas this was previously ambiguous.
While the figures above show a nearly complete recovery of symbols, it is hard to capture this in a few screenshots. The key here is the additional context that the analyst has during the reverse engineering of the sample, which saves time and avoids unnecessary assumptions.
For those who aren’t interested in the internal workings of Golang nor the inner workings of the scripts, or simply cannot wait to try the scripts on their own: they can be found here. The next section will provide a detailed overview of Golang’s internals and how the scripts use them.
Digesting gophers
To fully understand the scripts, one must understand several Golang concepts and structures. This section explains some of the used patterns, as well as Golang’s pclntab and moduledata structures. The aim here is to convey the purpose of these structures, rather than an exhaustive deep dive of them. Those who are familiar with Golang’s internals might find some corners that I’ve cut in this section, for brevity’s sake.
A brief note about Golang’s versioning: it’s easiest to read the version number when excluding the “1.” in front of it. For example, version 1.2 is earlier than version 1.18. To be precise: there are 16 versions in-between the two versions, released over a span of 9 years. Keep this in mind when reading the scripts and when dealing with Golang versioning.
Recurring patterns
An effect of not using high P-code is that some of the Golang code and structures are based on patterns of assembly instructions. Newer Golang versions can potentially break from these patterns, which requires maintenance. The upkeep increases when supporting more architectures. An excerpt of the dynamic string recovery script is shown in the figure below. In the excerpt, the load effective address (LEA) instruction is to-be followed by a move (MOV) instruction, after which the pattern resumes. Once a complete pattern matches, a string can be recovered and created in Ghidra.
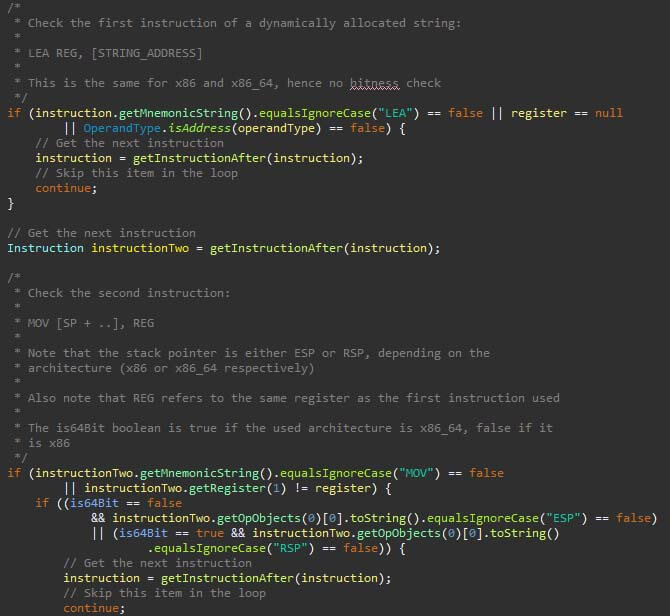
The pclntab
As documented by Russ Cox in 2013, the pclntab was introduced in Golang 1.2 . The name stands for “program counter line number table”, and contains information about the functions within the binary and their original source code line number. This data is used to create meaningful stack traces when an error occurs. The format of this table, taken from the linked material by Cox, is:
N pc0 func0 pc1 func1 pc2 func2 ... pc(N-1) func(N-1) pcN
In this notation, “N” is the table’s count, or size if you will. Each “funcN” entry is the offset value from the function symbol table, where a “Func” struct resides. This struct contains information, such as the function’s name and the offset thereof. The “pcN” value is the line number in the source file.
The pclntab is distinguished as a section with the name “.gopclntab” or “_gopclntab”, for Linux and MacOS-based binaries, respectively. For Windows, or any of the aforementioned platforms, one can search for the structure’s magic value. This magic value varies based on the Golang version of the binary.
Since the function names can be stripped from the binary, one would assume they’re removed completely. This is not the case, as the linked “Func” structs still contain their function name. These can, with the proper parsing, still be obtained, from which functions can be created or renamed. Note that functions which Ghidra missed, are created this way, ensuring a more complete overview of the binary during the analysis.
The moduledata
Within the moduledata struct, several other structures are present, such as the pclntab. The typelinks field is also included, which contains information about types within the binary. Since the moduledata contains the pclntab in its entirety (it’s a byte array field within the struct, not a pointer), searching for the pclntab’s magic value will lead one to the moduledata, albeit not necessarily at the start of the structure, depending on the Golang version.
The typelinks field is used to recover the type names and the field names within the types. Depending on the type it contains, as well as potentially nested types, these can be parsed and renamed within Ghidra. This provides a direct insight into the structures that the author used, along with the original field names.
Using the dragon to defeat the gophers
To use the supplied scripts, simply transfer all Java files to the Ghidra scripts folder. To find which folder is used by Ghidra, or to add a folder, open the script manager via Window -> Script Manager within the Code Browser, or press the green play button in the icon bar, as shown in the figure below. Once in the Script Manager, click on the bullet list to open the folder view, where folders can be checked, added, and/or removed.
Once the scripts have been added, press the two green arrows in the script manager to refresh the loaded scripts, and search for the (partial) script names. Alternatively, one can open the Golang tab in the tree view on the left side of the Script Manager to view all scripts which are tagged accordingly.
Conclusion
Ghidra is a life-saver when analyzing malware. Being free and open-source empowers the community to adopt, learn, and extend the tool, exactly as the NSA intended when making the tool public in 2019. These goals are aligned with the goals of Trellix: help analysts and malware researchers enhance their defensive capabilities. Contributing to the tool with re-usable scripts for Ghidra users is not our only goal: we also hope to inspire others to create and publicly release such extensions, as the defensive side hugely benefits from such activities.
As a final note, we would like to thank Dorka for her work on the initial scripts, upon which these scripts were built.
RECENT NEWS
-
May 19, 2026
Trellix Appoints Joe Chen as Chief Technology Officer
-
Apr 08, 2026
Trellix prevents enterprise data exposure in sanctioned and shadow AI
-
Mar 02, 2026
Trellix strengthens executive leadership team to accelerate cyber resilience vision
-
Feb 10, 2026
Trellix SecondSight actionable threat hunting strengthens cyber resilience
-
Dec 16, 2025
Trellix NDR Strengthens OT-IT Security Convergence
RECENT STORIES
Latest from our newsroom
Get the latest
Stay up to date with the latest cybersecurity trends, best practices, security vulnerabilities, and so much more.
Zero spam. Unsubscribe at any time.